

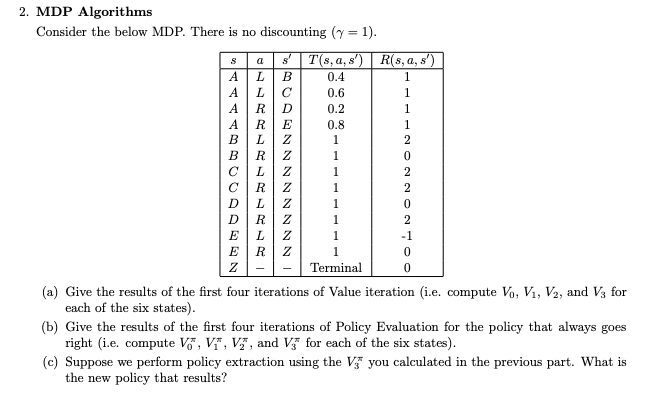
Question: MDP Algorithms Consider the below MDP . There is no discounting ( = 1 ) . ( a ) Give the results of the first
MDP Algorithms
Consider the below MDP There is no discounting
a Give the results of the first four iterations of Value iteration ie compute and for
each of the six states
b Give the results of the first four iterations of Policy Evaluation for the policy that always goes
right ie compute and for each of the six states
c Suppose we perform policy extraction using the you calculated in the previous part. What is
the new policy that results?
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock