

Question: My table basicly. 1. Split your data into train (80%) and test (20%) datasets using carets createDataPartition function. 2. Use the skim_to_wide function in skimr
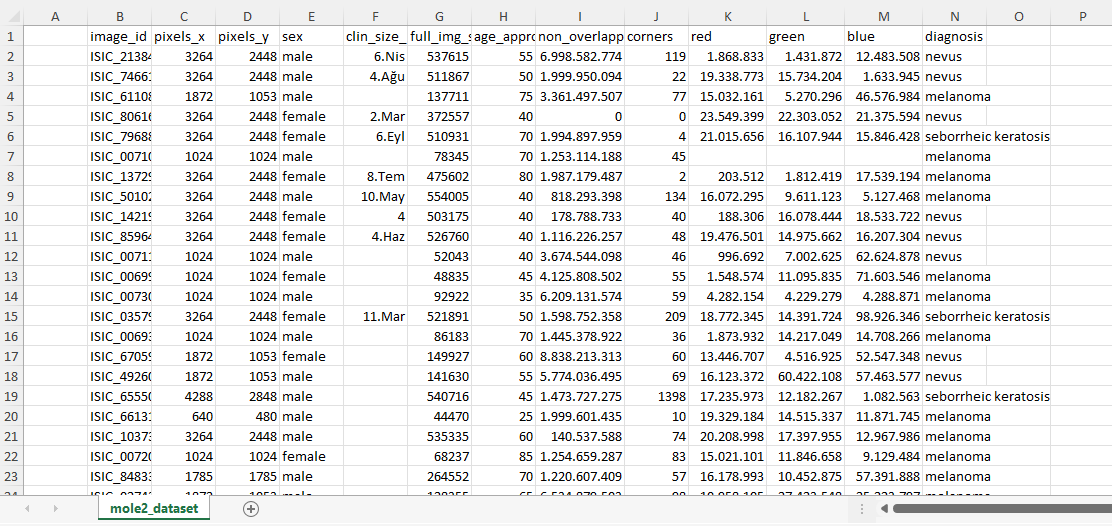 My table basicly.
My table basicly.
1. Split your data into train (80%) and test (20%) datasets using carets createDataPartition function.
2. Use the skim_to_wide function in skimr package, and provide descriptive stats for each column.
3. Predict and impute the missing values with k-Nearest Neighbors using preProcess function in caret. Comment!
4. After you impute missing values, use variable transformations. Convert all the numeric variables to range between 0 and 1, by setting method=range in preProcess function.
5. Use carets featurePlot() function to visually examine how the predictors influence the predictor variable. Comment!
6. a. Use train() function to build the machine learning model. Choose knn algorithm. b. Make predictions for test data using the predict() function. c. Construct the confusion matrix to compare the predictions (data) vs the actuals (reference).
7. a. Use train() function to build the machine learning model. Choose random forest algorithm. b. Make predictions for test data using the predict() function. c. Construct the confusion matrix to compare the predictions (data) vs the actuals (reference).
8. a. Use train() function to build the machine learning model. Choose nave bayes classification algorithm. b. Make predictions for test data using the predict() function. c. Construct the confusion matrix to compare the predictions (data) vs the actuals (reference).
9. Compare and make more and more comments about the final results you find in steps 6-8.
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts