

Question: Need to get the value using policy iterative policy evaluation above. The expected value from k = 0 until k =10 and k = infinity

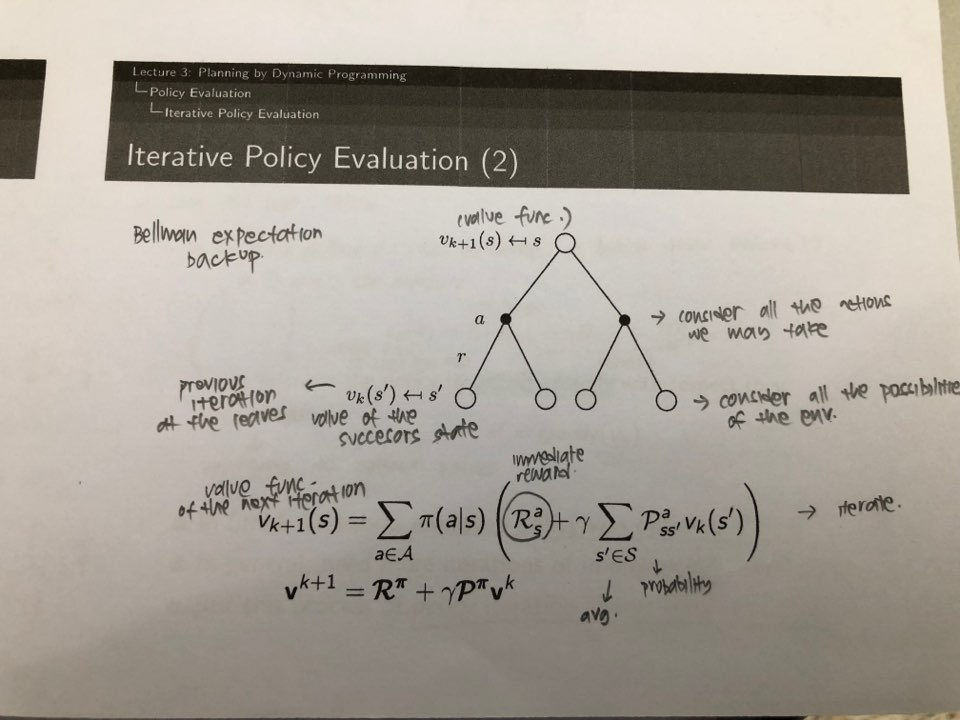
Need to get the value using policy iterative policy evaluation above.
The expected value from k = 0 until k =10 and k = infinity should be expected as the value shown below (Vk for the Random Policy)


c Programming ample: Small GridWorld Evaluating a Random Policy in the Small Gridworld 1 2 3 4 5 67 8 9 1011 on all transitions 12 Undiscounted episodic MDP ( = 1) Nonterminal states 1,, 14 One terminal state (shown twice as shaded squares) Actions leading out of the grid leave state unchanged Reward is-1 until the terminal state is reached . Agent follows uniform random policy Lecture 3 Planning by Dynamic Programming Policy Evaluation Example: Small Gridworld c Programming ample: Small GridWorld Evaluating a Random Policy in the Small Gridworld 1 2 3 4 5 67 8 9 1011 on all transitions 12 Undiscounted episodic MDP ( = 1) Nonterminal states 1,, 14 One terminal state (shown twice as shaded squares) Actions leading out of the grid leave state unchanged Reward is-1 until the terminal state is reached . Agent follows uniform random policy Lecture 3 Planning by Dynamic Programming Policy Evaluation Example: Small Gridworld
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts