

Question: Needed some help with this Python problem. Problem: Crawling a website and parsing the text to get the required information. Website crawling exist in every

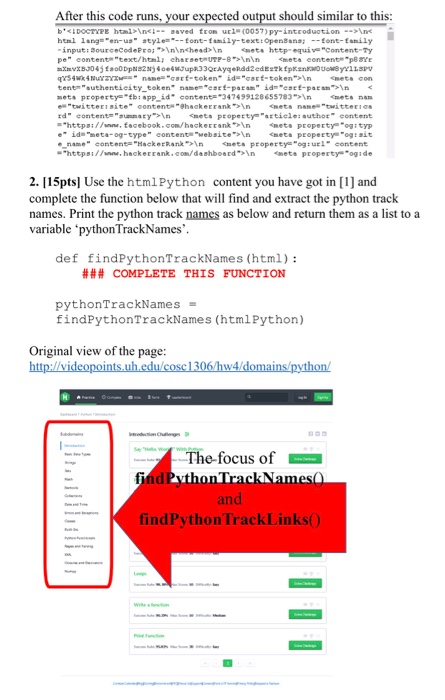

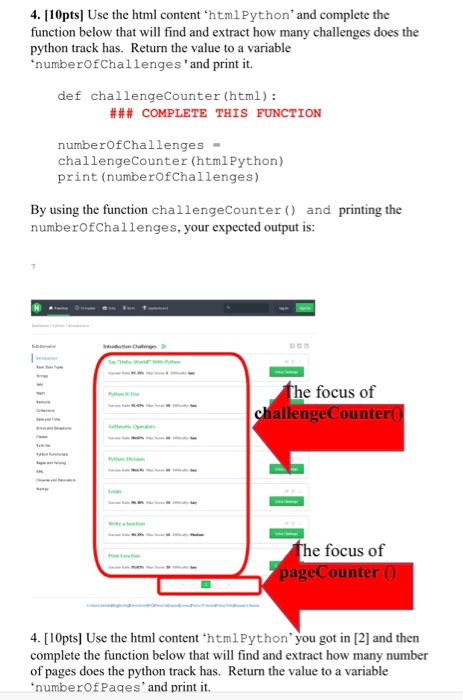

Problem: Crawling a website and parsing the text to get the required information. Website crawling exist in every programming languages. The goal is to access a website content through a hyperlink without using any browser Even though most of the websites can be crawled by using such programs, it is usually forbidden by website owners. There might be legal issues for an unauthorized crawling, so please use your code responsibly To avoid legal issues, instead of crawling an external website, we will crawl on some portion of it which is copied and located in our local servers: To read a website content, urllib module can be used from urllib.request import urlopen response = urlopen ('Some URL Links Here') .read () 1. [5pts] Complete the function below that will read and return the content of a site. You have several tasks to complete in the followings, please make sure that once you read the data correctly from the website, you don't call this function again and again to read the same data over and over. You read the content once and save the content with the variable named as htmlPython and print its content as below. def readUrl (url): ### COMPLETE THIS FUNCTION urlPython hw4/domains/python/ htmlPython - readUrl (urlPython) print (htmlPython)
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts