

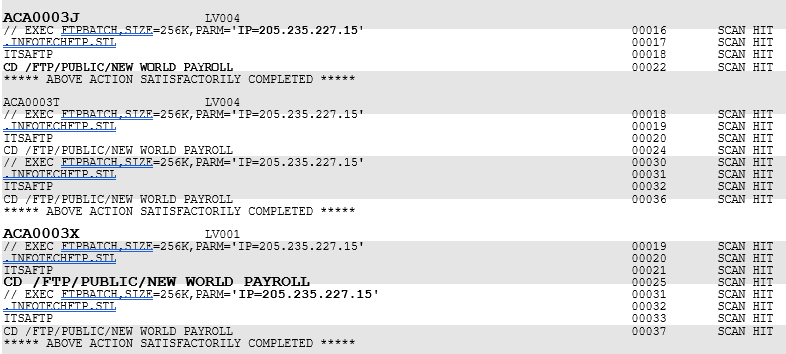
Question: Ok let's make this one simple need the JOB column to print data. The data starts with JC or AC lines
Ok let's make this one simple need the "JOB" column to print data. The data starts with JC or AC lines
import re
import pandas as pd
import subprocess
import sys
# Check if tabulate is installed
try:
import tabulate
except ImportError:
# Install tabulate if not found
subprocess.checkcallsysexecutable, m "pip", "install", "tabulate"
import tabulate
# Check if openpyxl is installed
try:
import openpyxl
except ImportError:
# Install openpyxl if not found
subprocess.checkcallsysexecutable, m "pip", "install", "openpyxl"
import openpyxl
# Define the file path using forward slashes
filepath C:UserscollbbDownloadstesttxt
outputfilepath C:UserscollbbDownloadsoutputtest.xlsx
# Read the data from the file
with openfilepath, r as file:
data file.read
# Split the data into lines
lines data.splitlines
# Initialize an empty list to store the processed data
processeddata
# Regular expressions for extracting data
ipregex rIPd
pathregex rCDsFTPPUBLICS
dateregex rddd # Adjusted date format
jobregex rJCS # Matches job names starting with JC
# Iterate through the lines and extract the data
i
while i lenlines:
line linesistrip
if line.startswith EXEC FTPBATCH":
try: # Add tryexcept for error handling
ipmatch researchipregex, line
ip ipmatch.group if ipmatch else None
except AttributeError:
ip None
printfWarning: Could not extract IP on line i
ftpaction "Upload" # Assuming FTPBATCH implies upload action
# Look ahead for the path and date
j i
path date None
while j lenlines and not linesjstartswith:
try:
pathmatch researchpathregex, linesj
if pathmatch:
path pathmatch.group
except AttributeError:
path None
printfWarning: Could not extract path on line j
try:
datematch researchdateregex, linesj
if datematch:
date datematch.group
except AttributeError:
date None
printfWarning: Could not extract date on line j
j
# Extract job information search within a window of lines
job None
for k in rangei mini lenlines: # Search the next lines
jobmatch researchjobregex, lineskstrip
if jobmatch:
job jobmatch.group
break # Stop searching once a job is found
# Append the extracted data to the list
processeddata.append
IP: ip
CD FTPPUBLIC: path,
"Date": date, # Add back if needed
FTPAction": ftpaction,
"Status": "Success",
"Job": job
i
# Create a pandas DataFrame from the processed data
df pdDataFrameprocesseddata
# Print the first rows of the DataFrame
printdfheadtomarkdownindexFalse, numalign"left", stralign"left"
# Create an Excel spreadsheet and save the DataFrame
with pdExcelWriteroutputfilepath, engine"openpyxl" as writer:
dftoexcelwriter sheetnameFTP Data", indexFalse
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock