

Question: #PLease Answer in Python Codeblock import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns Use pd.read_csv to read
#PLease Answer in Python Codeblock
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
Use pd.read_csv to read the cereals_data.csv file into a DataFrame called cereals_data
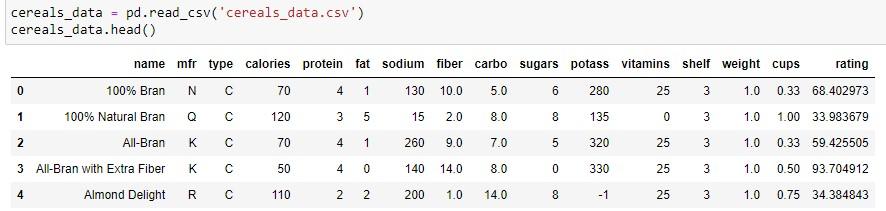
If you take a close look at this .csv file, you will find that some column names as well as some of the categorical values have extra whitespace on the left- and/or right-hand sides. For example, the column index unnamed: has a space after the colon.
Strip the whitespace off of the column names by using cereals_data.columns.str.strip(). The .str.strip() method can be applied to values within individual columns as well. Apply this method to the columns Name, Manuf, and Type. (Even if you print the first 5 rows again, it may not be immediately clear if you have successfully stripped the whitespace until you start accessing particular values.)
code: cereals_data.columns
Index(['name', 'mfr', ' type', 'calories', 'protein', 'fat', 'sodium', 'fiber', 'carbo', 'sugars', 'potass', 'vitamins', 'shelf', 'weight', 'cups', 'rating'], dtype='object')
B) The unnamed: column is not very useful, so permanently drop that column.
Additionally, to follow the pattern of abbreviations, rename Calories to Cal and Vitamins to Vit. (This can be done in one line.)
Again output the data frame dimensions and the first five rows to confirm these changes. Successfully performing these changes should demonstrate that the extraneous whitespace in the columns was removed.
C) Print the unique values in the columns Manuf, Type, and Shelf. You should find that there are 7 unique characters for Manuf, 'C' and 'H' for Type, and 1, 2, and 3 for Shelf. Change the Type column such that it uses 'cold' and 'hot' instead of 'C' and 'H' respectively. Output the first five rows to confirm this change.
cereals_data pd.read_csv('cereals_data.csv') cereals_data.head() 3 8 3 name mfr type calories protein fat sodium fiber carbo sugars potass vitamins shelf weight cups rating 0 100% Bran N 70 4 1 130 10.0 5.0 6 280 25 3 1.0 0.33 68.402973 1 100% Natural Bran Q 120 3 5 15 2.0 8.0 135 0 3 1.0 1.00 33.983679 2 All Bran K 70 4 1 260 9.0 7.0 5 320 25 3 1.0 0.33 59.425505 3 All-Bran with Extra Fiber K 4 0 140 14.0 8.0 0 330 25 3 1.0 0.50 93.704912 4 Almond Delight R 110 2 2 200 1.0 14.0 8 25 3 1.0 0.75 34.384843 50 c 2 2 -1
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts