

Question: Please fill the code below # your implementation In [1]: # import all packages import nltk from nltk import word_tokenize, pos_tag, ne_chunk from nltk import
![Please fill the code below # your implementation In [1]: # import](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2024/09/66f4eb05c0ad4_98166f4eb053848d.jpg)
 Please fill the code below # your implementation
Please fill the code below # your implementation
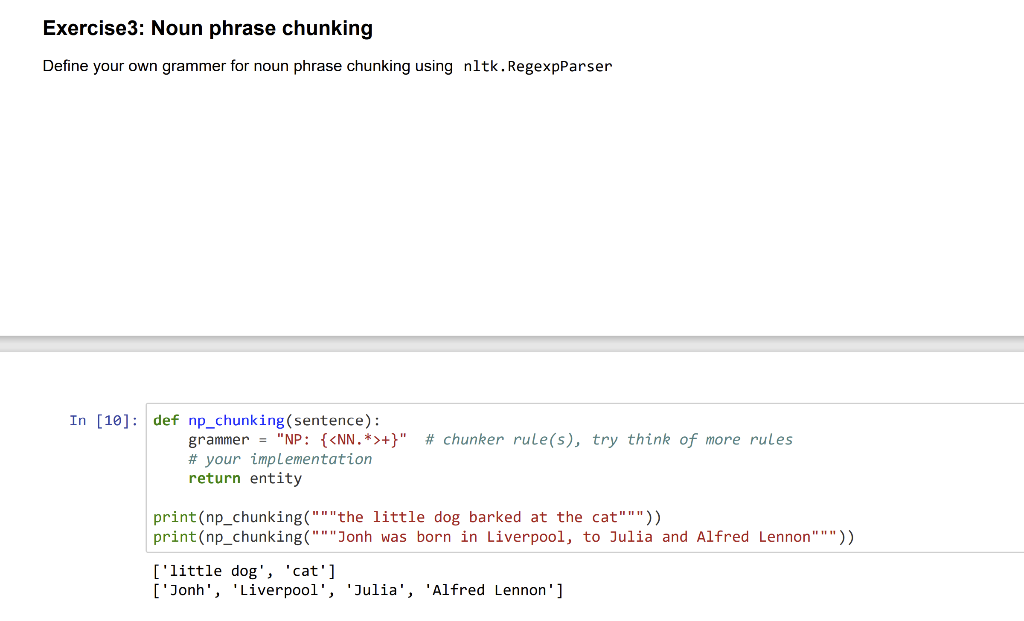
In [1]: # import all packages import nltk from nltk import word_tokenize, pos_tag, ne_chunk from nltk import Tree II II II raw = In [2]: # Tokenize sentence: """John was born in Liverpool, to Julia and Alfred Lennon" tokens = word_tokenize(raw) tokens Exercise 3: Noun phrase chunking Define your own grammer for noun phrase chunking using nltk. RegexpParser In [10]: def np_chunking (sentence): grammer = "NP: {
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts