

Question: Please provide the code to find out how many word types account for a third of all word tokens in Brown import nltk from nltk.corpus
Please provide the code to find out how many word types account for a third of all word tokens in Brown
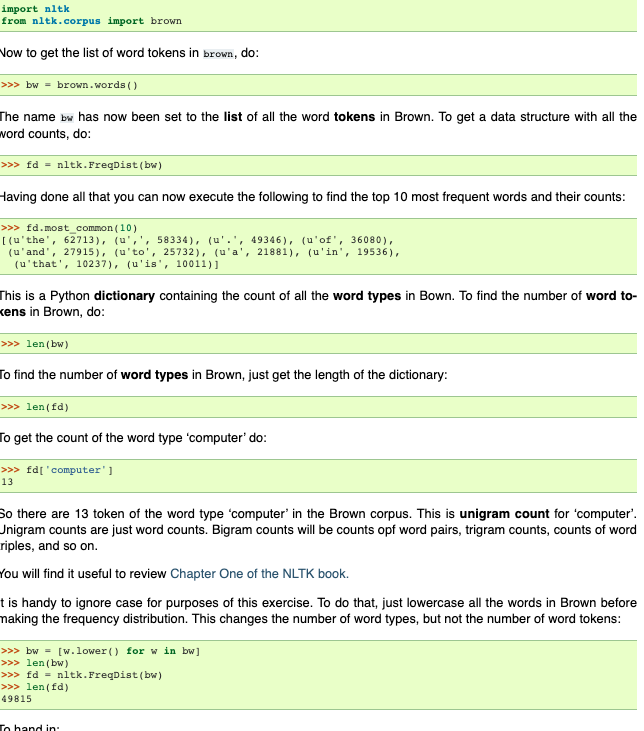
import nltk from nltk.corpus import brown Vow to get the list of word tokens in brown, do: >>> bw = brown.words() The name bw has now been set to the list of all the word tokens in Brown. To get a data structure with all the word counts, do: >>> fd = nltk. FreqDist(bw) Having done all that you can now execute the following to find the top 10 most frequent words and their counts: >>> fd.most common (10) [(u'the', 62713), (u',',58334), (u'.', 49346), (u'of', 36080), (u'and', 27915), (u'to', 25732), (u'a', 21881), (u'in', 19536), (u'that', 10237), (u'is', 10011)] This is a Python dictionary containing the count of all the word types in Bown. To find the number of word to- kens in Brown, do: >>> len (bw) To find the number of word types in Brown, just get the length of the dictionary: >>> len(fd) To get the count of the word type 'computer' do: >>> fd['computer'] 13 So there are 13 token of the word type 'computer' in the Brown corpus. This is unigram count for computer'. Jnigram counts are just word counts. Bigram counts will be counts opf word pairs, trigram counts, counts of word riples, and so on. You will find it useful to review Chapter One of the NLTK book. t is handy to ignore case for purposes of this exercise. To do that, just lowercase all the words in Brown before making the frequency distribution. This changes the number of word types, but not the number of word tokens: >>> bw = [w.lower() for win bw] >>> len(bw) >>> fd = nltk. FreqDist(b) >>> len(fd) 49815 To hand in
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts