

Question: Python Machine Learning supervised learning I have a csv, and I need help doing supervised learning with a test part and a train part (random
Python Machine Learning supervised learning
I have a csv, and I need help doing supervised learning with a test part and a train part (random selection). Then choose the best model among all the training models. As well as doing cross-validation and random forest. And create some graphics in order to chose the best predictor (ex: seaborn).
The types of my data frame are:
title object p float64 watchers int64 brand object color object speeds float64 type object used int64 dtype: object
Is it possible with the variables I have in my csv to create a supervised learning model that will be trained to recognize the data provided and categorize them according to the two sales categories (used=1, else 0), or a forecast of the average selling price of used items?
The first row is name of column:
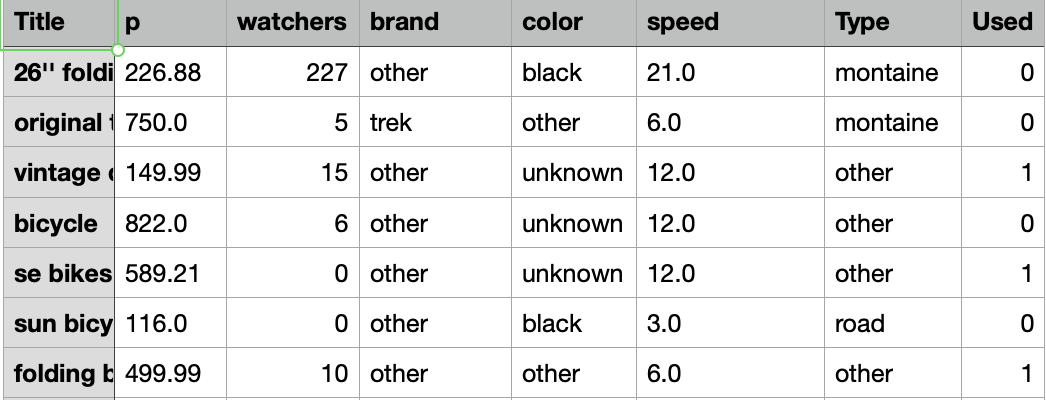
Title watchers brand color speed Type Used 26" foldi 226.88 227 other black 21.0 montaine 0 original 1 750.0 5 trek other 6.0 montaine 0 vintage ( 149.99 15 other unknown 12.0 other 1 bicycle 822.0 6 other unknown 12.0 other O se bikes 589.21 o other unknown 12.0 other 1 sun bicy 116.0 0 other black 3.0 road o folding 499.99 10 other other 6.0 other 1
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts