

Question: Python questions 1.Select the first 15 values from the created_at column of df and print only the HH:MM:SS part in each value, where H denotes
Python questions
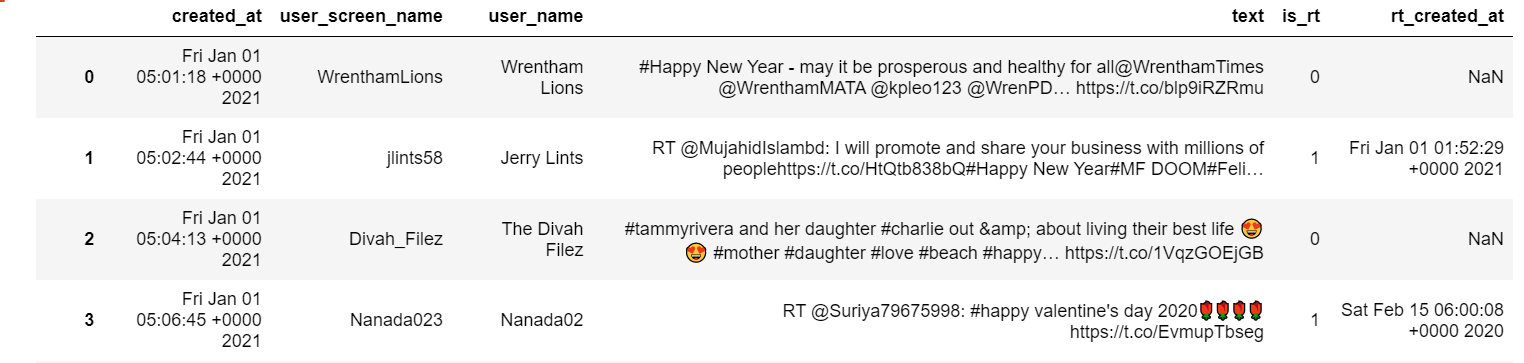
1.Select the first 15 values from the created_at column of df and print only the HH:MM:SS part in each value, where H denotes each digit in an hour, M each digit in a minute, and S each digit in a second. Rows in the printed output are separated by a new line.
2. Select the first 15 rows from df and print the values in each row in the following format: '[TYPE] TEXT' where TYPE is either 'Tweet' if the is_rt column value equals 0 or 'Retweet' if 1, and TEXT is the text column value. Rows are separated by two new lines.
The output for question 2 should be: [Tweet] #Happy New Year - may it be prosperous and healthy for all@WrenthamTimes @WrenthamMATA @kpleo123 @WrenPD https://t.co/blp9iRZRmu
3. Add a new column num_words to df such that each value in the column is the number word tokens in the text column value. (Use the split method to get a list of word tokens in a string).
4. Add a new column text_date to df such that each column value is a string in the format 'TEXT [posted on b DD, YYYY]', where TEXT is the first 50 characters in the text column value concatenated by '...'; b denotes the the abbreviated month name such as Jan and Feb; D denotes each digit in a day; Y denotes each digit in a year, all of which come from the created_at column value
The output for question 4 should be: #Happy New Year - may it be prosperous and healthy... [posted on Jan 01, 2021]
Thank you !!
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts