

Question: Q1: In this exercise, we look at how software techniques can extract instruction-level parallelism (ILP) in a common vector loop. The following loop is the


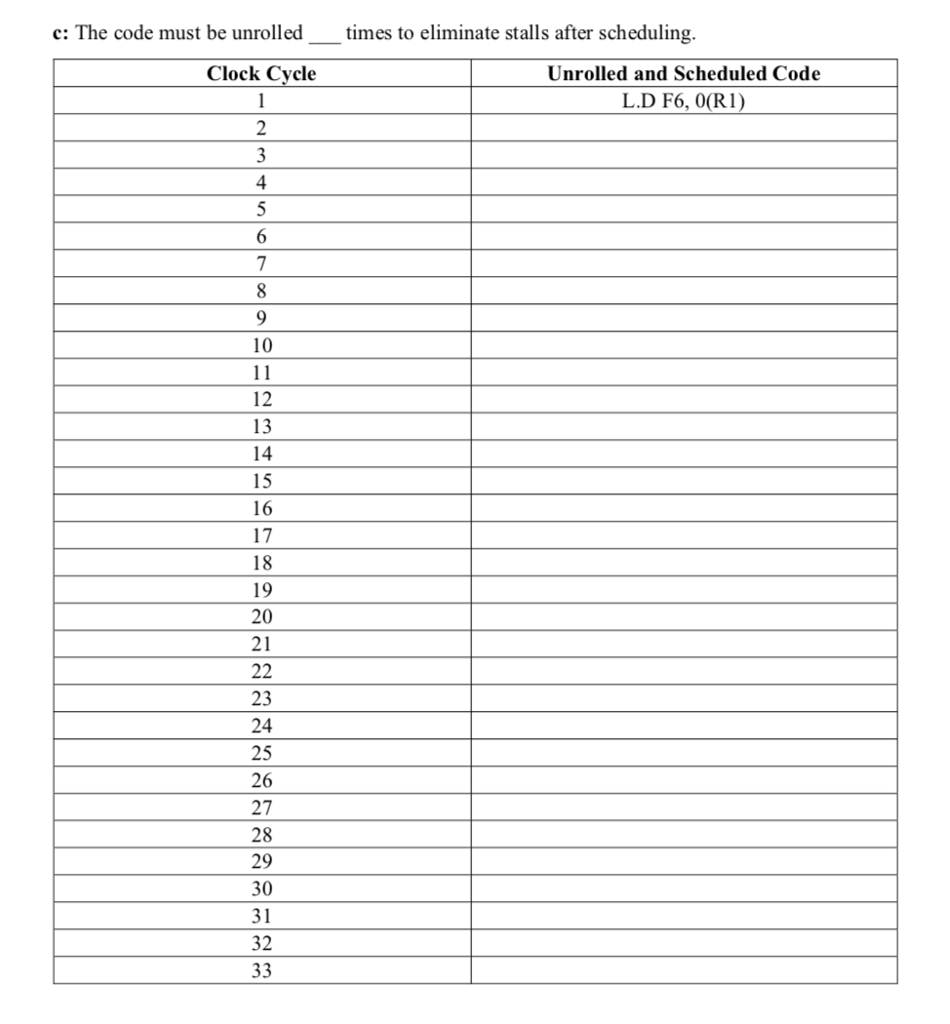
Q1: In this exercise, we look at how software techniques can extract instruction-level parallelism (ILP) in a common vector loop. The following loop is the so-called DAXPY loop (double- precision aX plus Y) and is the central operation in Gaussian elimination. The following code implements the DAXPY operation, Y= aX+ Y. Initially, F4 holds constant a, RI is set to the base address of array X, and R2 is set to the base address of array Y: foo: L.D MUL.D L.D ADD.D S. D DADDIU DADDIU DSLTU BNEZ F6, O(R1) F2, F6, F4 F8, O(R2) F8, F2, F8 F8, O(R2) RI, RI, #8 R2, R2, #8 R5, R1, R3 R5, foo load X(i) to Reg(F6) Reg(F2) = a*X(i) Reg(FS)-Y(i) Reg( F8) = a*X(i)+Y(i) store Reg(F8) to Y(i) increase X index increase Y index test: continue loop? loop if needed The table below shows the number of intervening clock cycles needed to avoid a stall. Assume that results are fully bypassed Instruction producing result FP multiply FP ALU o FP multiply FP ALU o Load Load Integer ALU op Integer ALU op Instruction using result FP Store FP Store FP ALU o FP ALU o Store Other than store Branch Integer ALU o Latency in clock cvcles 4 0 0 Q1: In this exercise, we look at how software techniques can extract instruction-level parallelism (ILP) in a common vector loop. The following loop is the so-called DAXPY loop (double- precision aX plus Y) and is the central operation in Gaussian elimination. The following code implements the DAXPY operation, Y= aX+ Y. Initially, F4 holds constant a, RI is set to the base address of array X, and R2 is set to the base address of array Y: foo: L.D MUL.D L.D ADD.D S. D DADDIU DADDIU DSLTU BNEZ F6, O(R1) F2, F6, F4 F8, O(R2) F8, F2, F8 F8, O(R2) RI, RI, #8 R2, R2, #8 R5, R1, R3 R5, foo load X(i) to Reg(F6) Reg(F2) = a*X(i) Reg(FS)-Y(i) Reg( F8) = a*X(i)+Y(i) store Reg(F8) to Y(i) increase X index increase Y index test: continue loop? loop if needed The table below shows the number of intervening clock cycles needed to avoid a stall. Assume that results are fully bypassed Instruction producing result FP multiply FP ALU o FP multiply FP ALU o Load Load Integer ALU op Integer ALU op Instruction using result FP Store FP Store FP ALU o FP ALU o Store Other than store Branch Integer ALU o Latency in clock cvcles 4 0 0
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts