

Question: Question 1: Consider the following data set: R4 Restaurant Type 1 Fast Food R2 Ethnic R3 Casual Dining Casual Dining R5 Casual Dining Fast Food
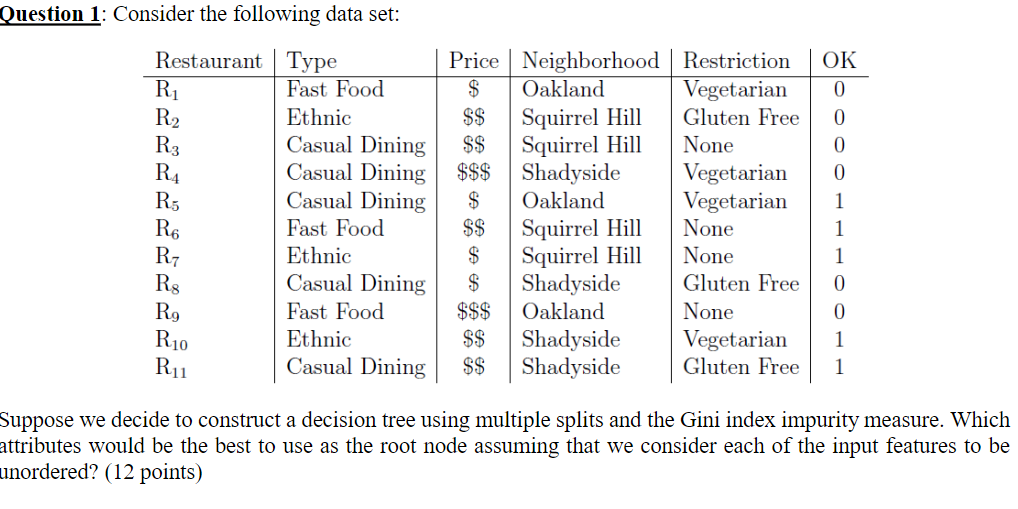
Question 1: Consider the following data set: R4 Restaurant Type 1 Fast Food R2 Ethnic R3 Casual Dining Casual Dining R5 Casual Dining Fast Food Ethnic RS Casual Dining Rg Fast Food Ethnic Ru1 Casual Dining Price Neighborhood Restriction $ Oakland Vegetarian $$ Squirrel Hill Gluten Free $$ Squirrel Hill None $$$ Shadyside Vegetarian $ Oakland Vegetarian $$ Squirrel Hill None $ Squirrel Hill None $ Shadyside Gluten Free $$$ Oakland None $$ Shadyside Vegetarian $$ Shadyside Gluten Free OK 0 0 0 0 1 1 1 0 0 1 1 R6 7 R10 Suppose we decide to construct a decision tree using multiple splits and the Gini index impurity measure. Which attributes would be the best to use as the root node assuming that we consider each of the input features to be unordered? (12 points) Question 1: Consider the following data set: R4 Restaurant Type 1 Fast Food R2 Ethnic R3 Casual Dining Casual Dining R5 Casual Dining Fast Food Ethnic RS Casual Dining Rg Fast Food Ethnic Ru1 Casual Dining Price Neighborhood Restriction $ Oakland Vegetarian $$ Squirrel Hill Gluten Free $$ Squirrel Hill None $$$ Shadyside Vegetarian $ Oakland Vegetarian $$ Squirrel Hill None $ Squirrel Hill None $ Shadyside Gluten Free $$$ Oakland None $$ Shadyside Vegetarian $$ Shadyside Gluten Free OK 0 0 0 0 1 1 1 0 0 1 1 R6 7 R10 Suppose we decide to construct a decision tree using multiple splits and the Gini index impurity measure. Which attributes would be the best to use as the root node assuming that we consider each of the input features to be unordered? (12 points)
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts