

Question: Question 19. Markov Decision Processes Consider the MDP in the figure below. There are two states, S1 and S2, and two actions, switch and stay.
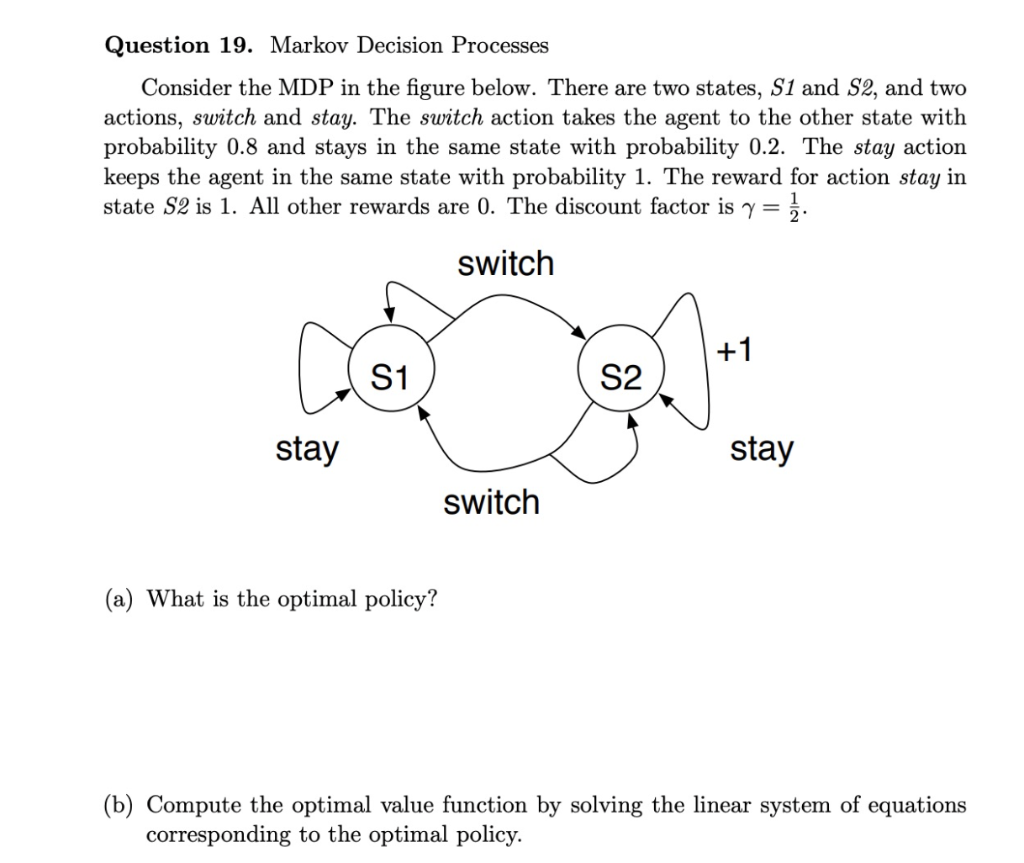

Question 19. Markov Decision Processes Consider the MDP in the figure below. There are two states, S1 and S2, and two actions, switch and stay. The switch action takes the agent to the other state with probability 0.8 and stays in the same state with probability 0.2. The stay action keeps the agent in the same state with probability 1 . The reward for action stay in state S2 is 1 . All other rewards are 0 . The discount factor is =21. (a) What is the optimal policy? (b) Compute the optimal value function by solving the linear system of equations corresponding to the optimal policy. (c) Suppose that you are doing synchronous value iteration to compute the optimal state-value function. You start with all value estimates equal to 0 . Show the value estimates after 1 and 2 iterations respectively
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts