

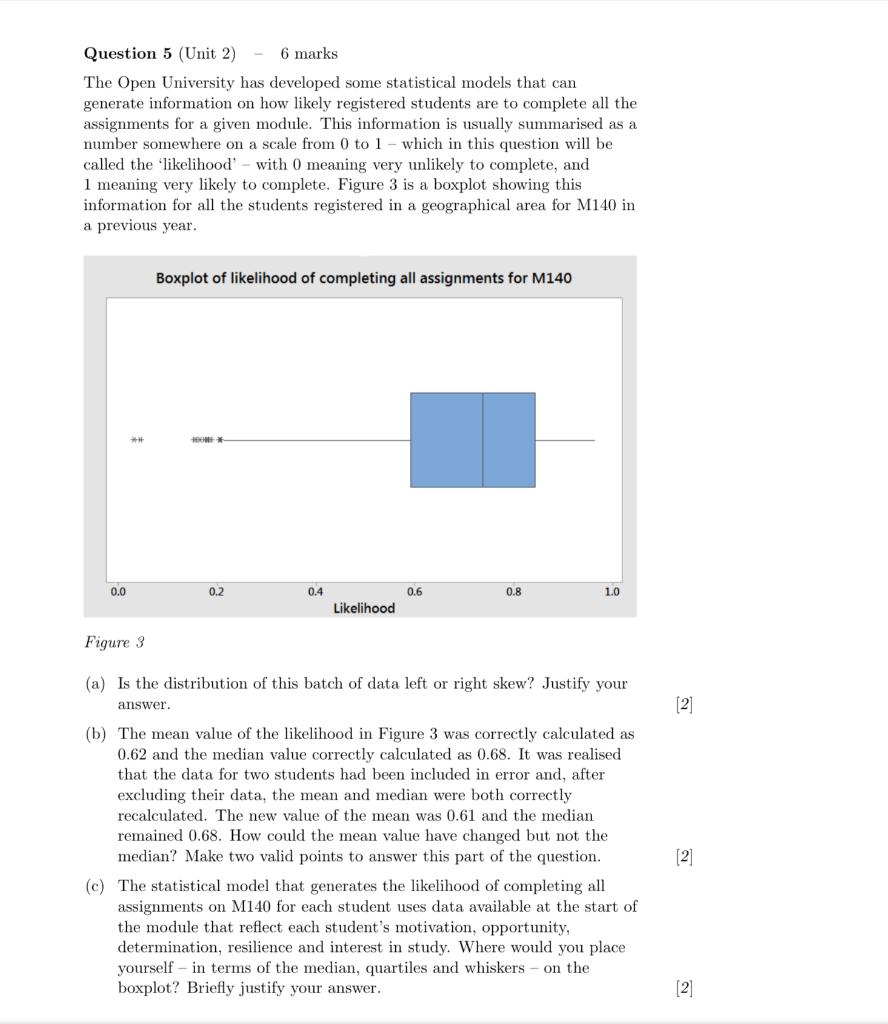
Question: Question 5 (Unit 2) 6 marks The Open University has developed some statistical models that can generate information on how likely registered students are to
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock