

Question: Task 0 - feature definition Write a python function that takes the training set spam_train.csv as input and output a list of words (referred to





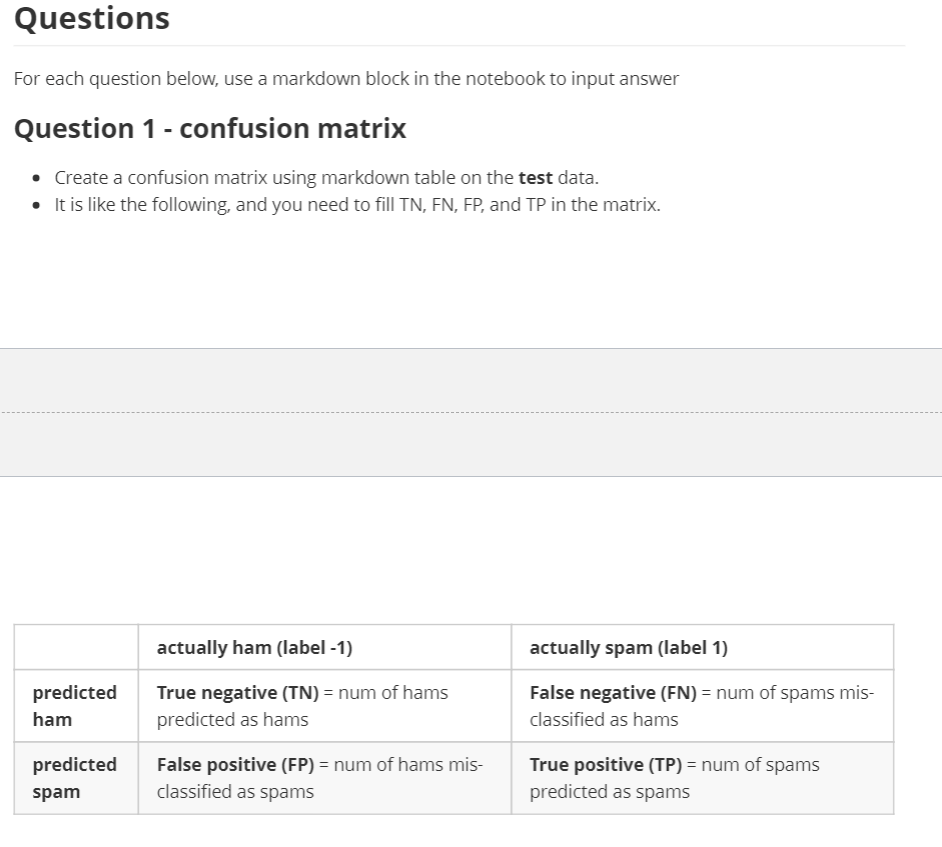


Task 0 - feature definition Write a python function that takes the training set spam_train.csv as input and output a list of words (referred to as feature words) that will be used as features. As suggested, you can use the top n most frequent words in all messages in the training samples. I will let you decide n (should be no less than 100). o You need to remove the stop words from the text. Stop words are common words which do not add predictive value because they are found everywhere. A list of stop words in English is also provided on Canvas. when everyone is a super, no one will be a super]. Task 1 - feature extraction Write a python function that takes as input 1) feature word list and 2) a sms message and output a feature vector, which should have the same length as the feature word list. Task 2 - Xs and Ys preparation Write a python function that takes as input spam_train.csv and spam_test.csv , and output X_train, Y_train, X_test, and Y_test , which are numpy arrays. X_train is the feature matrix (size is num_train_examples by num_features+1 ) for training data. . For each sample, zo is always 1. Check slides for details. Y_train is the target array (size is num_train_examples for training data. X_test is the feature matrix (size is num_test_examples by num_features+1 ) for test data. Y_test is the target array (size is num_train_examples) for test data. o o o Task 3 - pocket algorithm implementation Write a python function to implement the pocket algorithm (see lecture notes). The function will take X_train and Y_train as input, and output a hypothesis (i.e., an array of weights). Task 4 - performance e valuation Write a python function to evaluate the accuracy of the hypothesis produced from task 3. The function should take as input the hypothesis from task 3 (aka the weight array), X, and Y, and output the model accuracy. o Test this function using both training and testing data. Questions For each question below, use a markdown block in the notebook to input answer Question 1 - confusion matrix Create a confusion matrix using markdown table on the test data. It is like the following, and you need to fill TN, FN, FP, and TP in the matrix. actually ham (label - 1) actually spam (label 1) predicted ham True negative (TN) = num of hams predicted as hams False negative (FN) = num of spams mis- classified as hams predicted spam False positive (FP) = num of hams mis- classified as spams True positive (TP) = num of spams predicted as spams Question 2 - training and testing performance What are the accuracies of your hypothesis on training and testing data. Question 3 - err or analysis Manually examine the samples in testing set) that your algorithm made errors on, list three typical samples your hypothesis made errors on. What features would have helped classify them correctly? Submission Your submission should be a notebook file (an ipynb file). The ipynb file should be named using format firstname_lastname_ account_p1, for example, mine is Your notebook should contain all required functions, testing scripts, outputs, plots (if any), and answers to the required questions. Task 0 - feature definition Write a python function that takes the training set spam_train.csv as input and output a list of words (referred to as feature words) that will be used as features. As suggested, you can use the top n most frequent words in all messages in the training samples. I will let you decide n (should be no less than 100). o You need to remove the stop words from the text. Stop words are common words which do not add predictive value because they are found everywhere. A list of stop words in English is also provided on Canvas. when everyone is a super, no one will be a super]. Task 1 - feature extraction Write a python function that takes as input 1) feature word list and 2) a sms message and output a feature vector, which should have the same length as the feature word list. Task 2 - Xs and Ys preparation Write a python function that takes as input spam_train.csv and spam_test.csv , and output X_train, Y_train, X_test, and Y_test , which are numpy arrays. X_train is the feature matrix (size is num_train_examples by num_features+1 ) for training data. . For each sample, zo is always 1. Check slides for details. Y_train is the target array (size is num_train_examples for training data. X_test is the feature matrix (size is num_test_examples by num_features+1 ) for test data. Y_test is the target array (size is num_train_examples) for test data. o o o Task 3 - pocket algorithm implementation Write a python function to implement the pocket algorithm (see lecture notes). The function will take X_train and Y_train as input, and output a hypothesis (i.e., an array of weights). Task 4 - performance e valuation Write a python function to evaluate the accuracy of the hypothesis produced from task 3. The function should take as input the hypothesis from task 3 (aka the weight array), X, and Y, and output the model accuracy. o Test this function using both training and testing data. Questions For each question below, use a markdown block in the notebook to input answer Question 1 - confusion matrix Create a confusion matrix using markdown table on the test data. It is like the following, and you need to fill TN, FN, FP, and TP in the matrix. actually ham (label - 1) actually spam (label 1) predicted ham True negative (TN) = num of hams predicted as hams False negative (FN) = num of spams mis- classified as hams predicted spam False positive (FP) = num of hams mis- classified as spams True positive (TP) = num of spams predicted as spams Question 2 - training and testing performance What are the accuracies of your hypothesis on training and testing data. Question 3 - err or analysis Manually examine the samples in testing set) that your algorithm made errors on, list three typical samples your hypothesis made errors on. What features would have helped classify them correctly? Submission Your submission should be a notebook file (an ipynb file). The ipynb file should be named using format firstname_lastname_ account_p1, for example, mine is Your notebook should contain all required functions, testing scripts, outputs, plots (if any), and answers to the required questions
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts