

Question: Task 2.A Complete the function below which takes in a frame, a number of standard deviations, and the name of a label column. This function
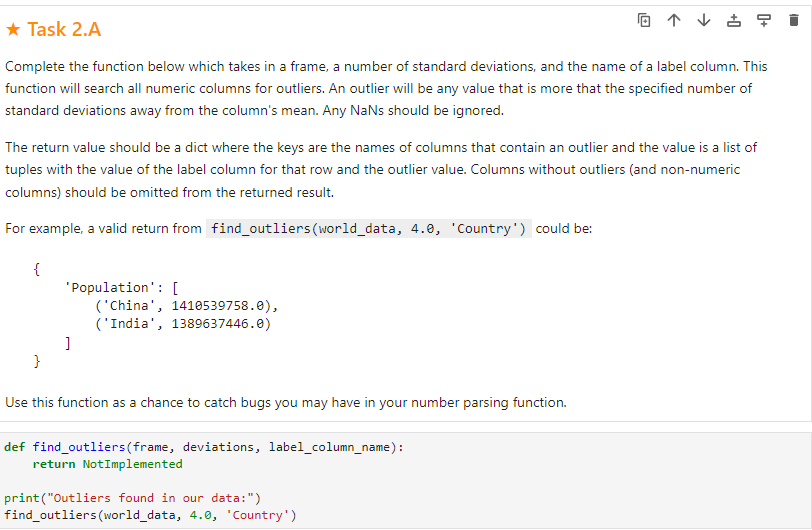
Task 2.A Complete the function below which takes in a frame, a number of standard deviations, and the name of a label column. This function will search all numeric columns for outliers. An outlier will be any value that is more that the specified number of standard deviations away from the column's mean. Any NaNs should be ignored. The return value should be a dict where the keys are the names of columns that contain an outlier and the value is a list of tuples with the value of the label column for that row and the outlier value. Columns without outliers (and non-numeric columns) should be omitted from the returned result. For example, a valid return from find_outliers(world_data, 4.0, 'Country') could be: Population:[(China,1410539758.0),(India,1389637446.0) ] Use this function as a chance to catch bugs you may have in your number parsing function. def find_outliers(frame, deviations, label_column_name): return Notimplemented print("Outliers found in our data:") find_outliers(world_data, 4.0, 'Country')
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts