

Question: TF-idf problem In this problem, you are asked to write code to compute the TF-IDF for terms in a document collection 2.1 Inverted Index Creation
TF-idf problem
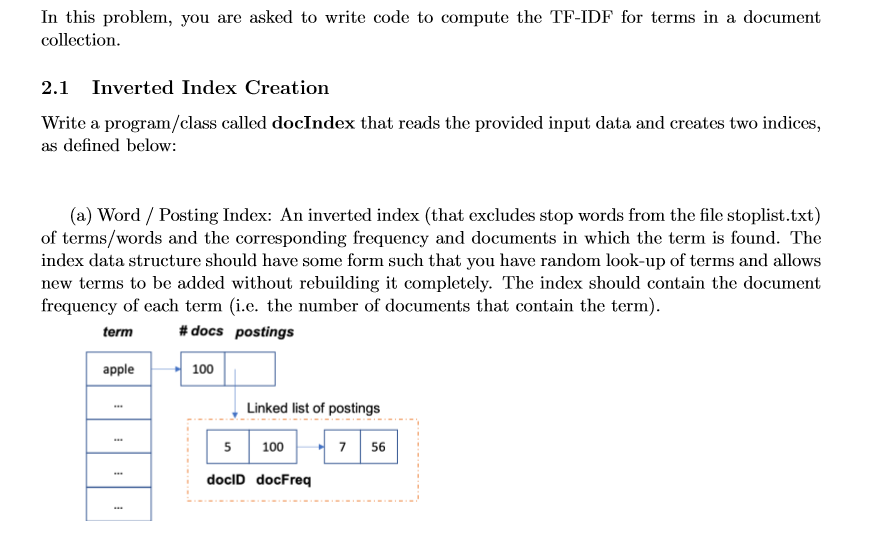

In this problem, you are asked to write code to compute the TF-IDF for terms in a document collection 2.1 Inverted Index Creation l input data a as defined below (a) Word / Posting Index: An inverted index (that excludes stop words from the file stoplist.txt) of terms/words and the corresponding frequency and documents in which the term is found. The index data structure should have some form such that you have random look-up of terms and allows new terms to be added without rebuilding it completely. The index should contain the document frequency of each term (i.e. the number of documents that contain the term) term #docs postings apple 100 Linked list of postings 5 100 docID docFreq (b) Document index: An inverted index that contains the number of terms in each document. docID # terms in doc 106 2.2 Test Program Write a program/class called test which will utilize the created indices to compute the tf-idf term weightings Prompt the user for a term. If the term is in the word index, the program should display a list of the postings for that term. For each posting, it should generate the term weightings, tf, idf, and tf-idf in that order separated by commas. If the term is not in the inverted file, it should display a suitable message. The program should loop until the user enter "QUIT" In this problem, you are asked to write code to compute the TF-IDF for terms in a document collection 2.1 Inverted Index Creation l input data a as defined below (a) Word / Posting Index: An inverted index (that excludes stop words from the file stoplist.txt) of terms/words and the corresponding frequency and documents in which the term is found. The index data structure should have some form such that you have random look-up of terms and allows new terms to be added without rebuilding it completely. The index should contain the document frequency of each term (i.e. the number of documents that contain the term) term #docs postings apple 100 Linked list of postings 5 100 docID docFreq (b) Document index: An inverted index that contains the number of terms in each document. docID # terms in doc 106 2.2 Test Program Write a program/class called test which will utilize the created indices to compute the tf-idf term weightings Prompt the user for a term. If the term is in the word index, the program should display a list of the postings for that term. For each posting, it should generate the term weightings, tf, idf, and tf-idf in that order separated by commas. If the term is not in the inverted file, it should display a suitable message. The program should loop until the user enter "QUIT
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts