

Question: The author uses the Case Study 12.13: Web Crawler to demonstrate how to read text from Web pages, parse out URLs and store them in
The author uses the Case Study 12.13: Web Crawler to demonstrate how to read text from Web pages, parse out URLs and store them in "stacks" created with ArrayLists, and crawl (change) to the URLs on each found page.
This assignment uses the program found on page 485 in your textbooks.

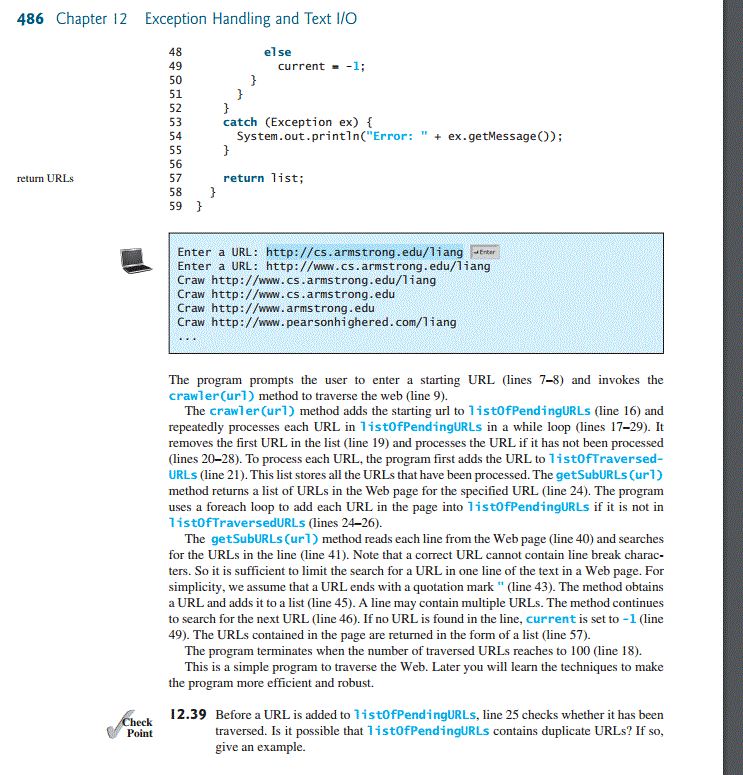
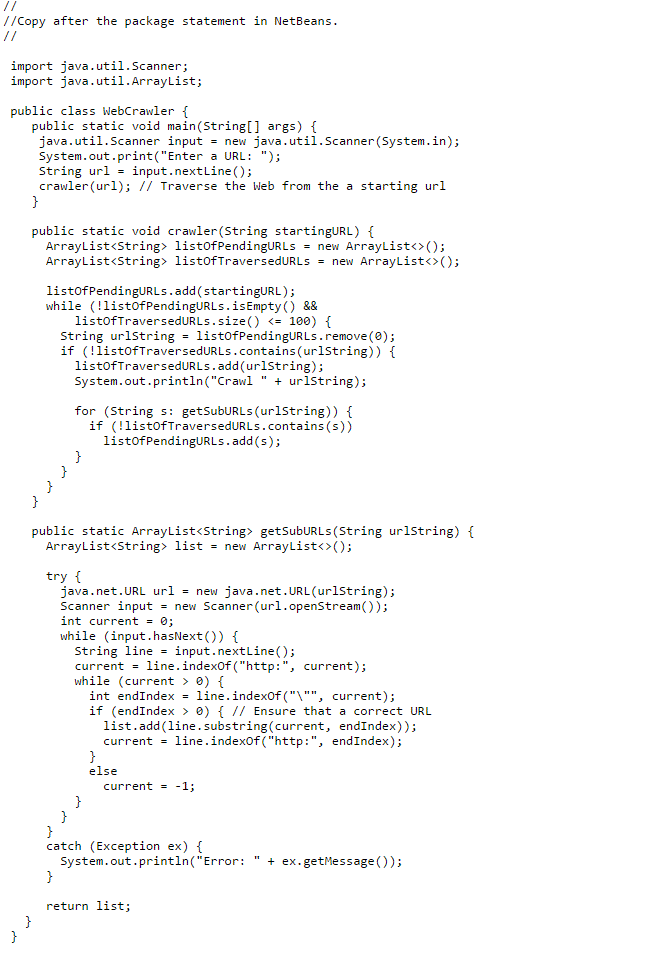
The java.net.URL url = new java.net.URL(urlString) line (36) in the getSubURLs() method actually loads the Web page into your Web browser. We are first going to create a new NetBeans project and copy the program into the Class file. We will then test the program with a specific URL. We will then modify the program to identify the URLs found only in the test URL without actually changing pages as part 2. Make sure you read the Help document for the snippet Assignment. PLEASE NOTE: The page numbers referenced below are from the program listing 12.18 found on page 485 in your textbooks. As part 1, in NetBeans create a project called "{YourLastName}SnippetWeek06 replacing {YourLastName} including the brackets with your Last Name. Let NetBeans create a main() method. Then, copy and paste the WebCrawler.txt file into the class with the main method and replace the class name WebCrawler with the name that matches your class. Execute the program using the test URL:

Test urls.

https://www.google.com
https://www.w3schools.com
http://www.msn.com
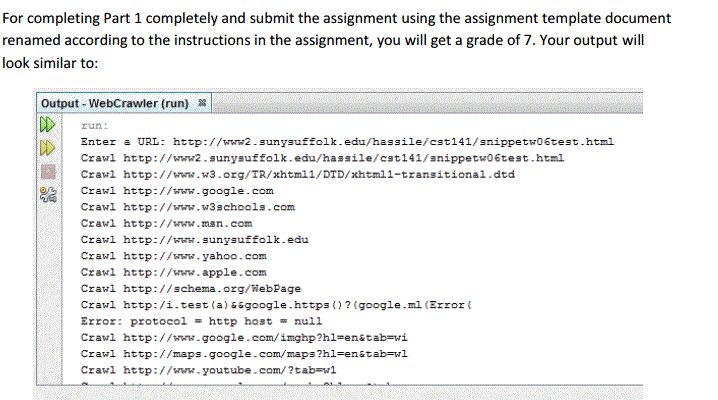
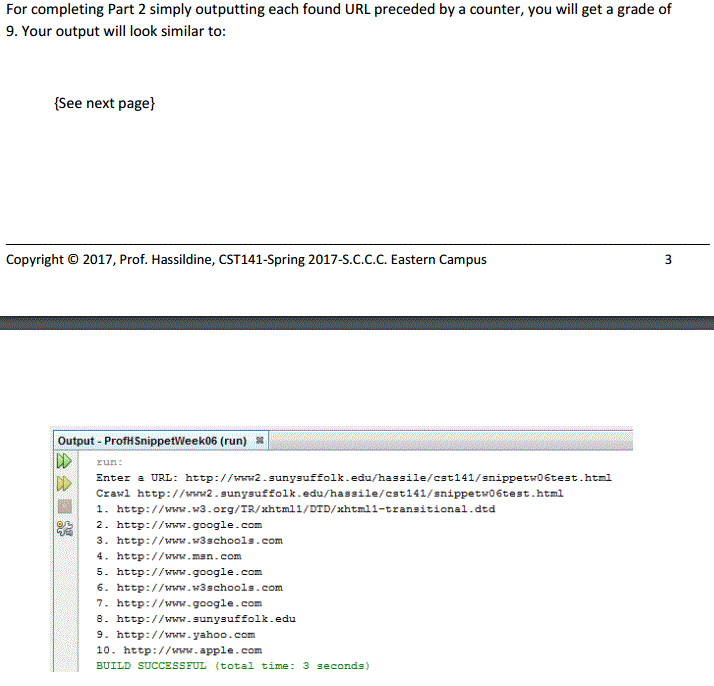
As part 2, create a project called "{YourLastName}SnippetWeek06Part2 replacing {YourLastName} including the brackets with your Last Name. Let NetBeans create a main() method. Then, copy and paste the WebCrawler.txt file into the class with the main method and replace the class name WebCrawler with the name that matches your class. You are to modify the program to identify the URLs contained just in the page the user enters from the prompt. You are to identify which line the URL appears in (which can be done as a simple variable that is incremented after every line is read), and the iteration (# of times) the repeated URL (if it is repeated that is) is appearing. Lines 24 - 27 are what causes a URL to be loaded as the source of our input. Comment them out and "getSubURLs()" will not be executed. Then make some modifications to perform the printing as stated above. Make sure you read the Help document for this assignment. For the output, use the same test page referenced above.\
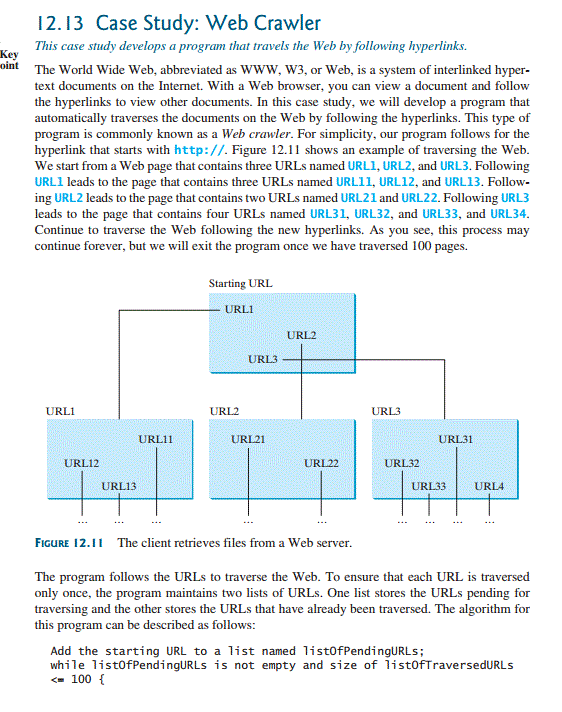
I 2.13 Case Study: Web Crawler This case study develops a program that travels the Web by following hyperlinks. oint The World Wide Web, abbreviated as www. W3, or Web, is a system of interlinked hyper- text documents on the Internet. With a Web browser, you can view a document and follow the hyperlinks to view other documents. In this case study, we will develop a program that automatically traverses the documents on the Web by following the hyperlinks. This type of program is commonly known as a Web crawler. For simplicity, our program follows for the hyperlink that starts with http://. Figure 12.11 shows an example of traversing the Web. We start from a Web page that contains three URLs named URLI,URL2, and URL3. Following URLI leads to the page that contains three URLs named URLll, URL12, and URL13. Follow ing URL2 leads to the page that contains two URLs named URL21and URL22. Following URL3 leads to the page that contains four URLs named URL31, URL32, and URL33, and URL34. Continue to traverse the Web following the new hyperlinks. As you see, this process may continue forever, but we will exit the program once we have traversed 100 pages. Starting URL URLI URL2 URL3 URL1 URL2 URL3 UR121 URL31 URL11. URL12 URL32 UR133 URL13 URLA FIGURE 12.II The client retrieves files from a Web server. The program follows the URLs to traverse the Web. To ensure that each URL is traversed only once, the program maintains two lists of URLs. One list stores the URLs pending for traversing and the other stores the URLs that have already been traversed. The algorithm for this program can be described as follows: Add the starting URL to a list named listofPendingURLs; while listofPendingURLs is not empty and size of listofTraversedURLs 100
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts