Question: This is the dictionary class This is the kvpair This is the pronunciation file: This is the UALDictionary This is the starting code given use

 This is the dictionary class
This is the dictionary class
This is the kvpair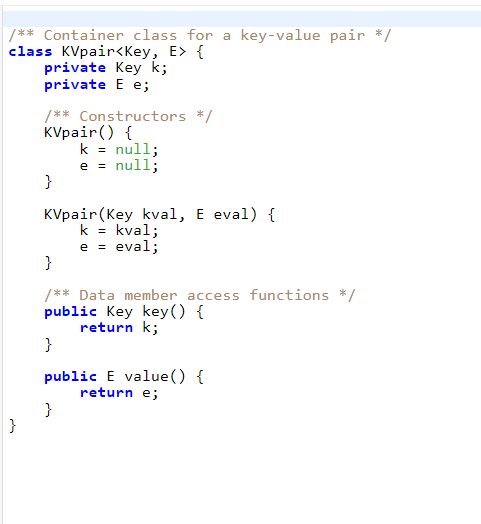 This is the pronunciation file:
This is the pronunciation file:
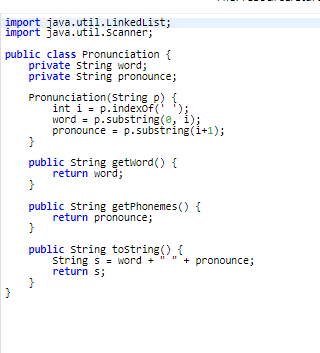 This is the UALDictionary
This is the UALDictionary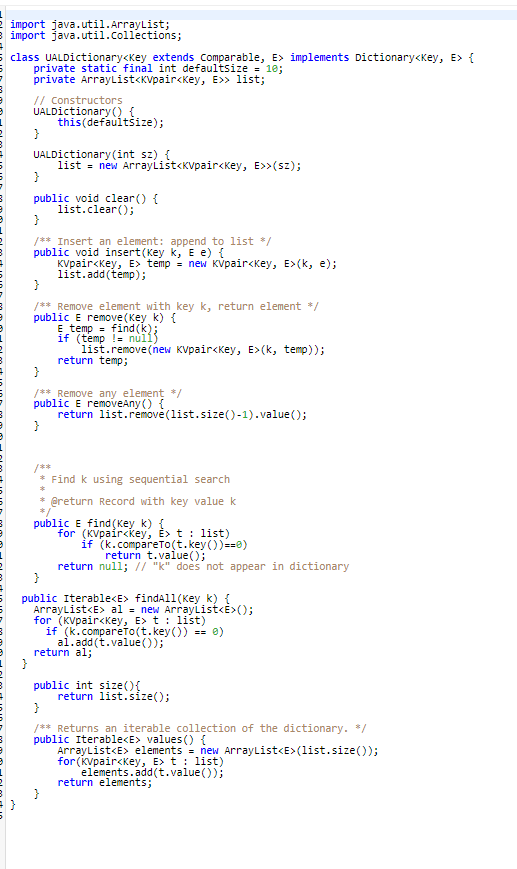 This is the starting code given use either one of the dictionaries either UALDictionary or OALDictionary:
This is the starting code given use either one of the dictionaries either UALDictionary or OALDictionary: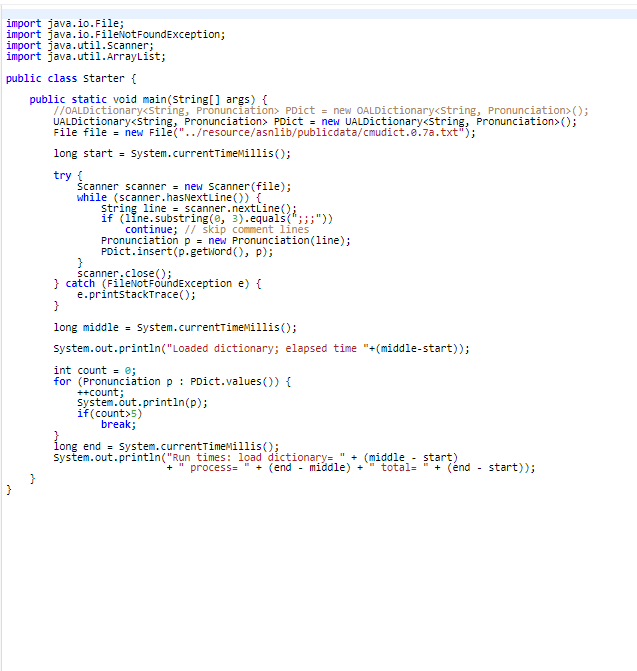 This is the OALDictionary:
This is the OALDictionary:
import java.util.ArrayList;
class OALDictionary implements Dictionary { private static final int defaultSize = 10; private ArrayList> list;
// Constructors OALDictionary() { this(defaultSize); }
OALDictionary(int sz) { list = new ArrayList>(sz); }
public void clear() { list.clear(); }
/** Insert an element: append to list */ public void insert(Key k, E e) { KVpair temp = new KVpair(k, e); int i = 0; while ((i 0)) ++i; list.add(i, temp); } /** Remove element with key k, return element */ public E remove(Key k) { E temp = find(k); if (temp != null) list.remove(new KVpair(k, temp)); return temp; } /** Remove any element */ public E removeAny() { return list.remove(list.size()-1).value(); }
/** * Find k using sequential search * * @return Record with key value k */ public E sfind(Key k) { for (KVpair t : list) if (k.compareTo(t.key()) == 0) return t.value(); return null; // "k" does not appear in dictionary }
/** * Find k using binary search * * @return Record with key value k */ public E find(Key k) { int low = 0; int hi = list.size() - 1; int mid = (low + hi) / 2; while (low 0) low = mid+1; else hi = mid-1; mid = (low + hi) / 2; } return null; // "k" does not appear in dictionary } /* findAll implementation using inefficient sequential search. * */ public Iterable sfindAll(Key k) { ArrayList al = new ArrayList(); for (KVpair t : list) if (k.compareTo(t.key()) == 0) al.add(t.value()); return al; } public Iterable findAll(Key k) { ArrayList al = new ArrayList(); int fidx = -1; int low = 0; int hi = list.size() - 1; int mid = (low + hi) / 2; while ((low 0) low = mid+1; else hi = mid-1; mid = (low + hi) / 2; } if(fidx =0;--i) if(k.compareTo(list.get(i).key()) != 0) break; fidx = i+1; // the first instance of key k for(i=fidx; i public int size() { return list.size(); }
/** Returns an iterable collection of the dictionary. */ public Iterable values() { ArrayList elements = new ArrayList(list.size()); for (KVpair t : list) elements.add(t.value()); return elements; } }
Relevant topic: Dictionaries. The purpose of this assignment is to gain familiarity with dictionaries. A homophone is one of two or more words that are pronounced alike but are different in meaning or spelling; for example, the words "two", "too", and "to". Write a Java program that uses one of the implementations of the dictionary interface that we have discussed to find the largest set of words that are homophones. Use only UALDictionary or OALDictionary, and do not use data structures that we have not covered so far in the course (for example hash maps or sorting algorithms other than insertion sort or selection sort). The file "cmudict.0.7a.txt" on Vocareum contains a pronunciation dictionary downloaded from The page also contains a detailed description of the pronunciation dictionary. The file consists of lines of the form ABUNDANT AHO B AH1 N D AHO N T The first string is the word, which is followed by one or more phonemes (or phones) that describe the pronunciation of the word. There are 39 phonemes occurring in North American English that are used in the dictionary. The collection of 39 symbols is known as the Arpabet, for the Advanced Research Projects Agency (ARPA), which developed it in the 1970 's in connection with research on speech understanding. The starter code on Vocareum contains several files you can use. UALDictionary.java is a class that implements the dictionary interface using an unordered array list. OALDictionary.java is a class that implements the dictionary interface using an ordered array list. The array list stores (key, value) pairs as described in the class KVpair.java. Pronunciation.java is a class that stores and manages access to a (word, phonemes) pair. There is also a program Starter.java that shows how you can read in the cmu dictionary (skipping comments and so on). Call your program MaxHomophones. The input is a single positive integer n. If the largest set of homophones in the first n lines of the pronunciation dictionary is of size k, then your program should print out k on the fist line, followed by k homophones, each on a new line. If there is more than one collection of k homophones, your program should print out each group, separated by a blank line. The output should be all upper case for consistency with the pronunciation dictionary. For example, if the input is 1000 then the correct output is 5 ABBE ABBEY ABBIE It would also be correct if the order of the two groups of homophones was reversed. If the input exceeds the size of the dictionary, the output should be the same as if the input were the size of the dictionary. Scoring: The grading will be based on five test problems, each counting two points. The score will be 0 for a test problem if: (1) the output is incorrect; (2) the program runs for more than 10 minutes; (3) the program uses data structures or algorithms that we have not covered in the course. Exercise. Considering only the dictionary operations insert, remove, and find, give the worst-case total running time and a sequence of n operations that have that running time if the dictionary is implemented as: (1) an unordered array list; (2) an ordered array list; State any assumptions you make about the implementations


