

Question: This question is solved I want another solution //I get errors when running the codes // I get errors when running the codes // I
This question is solved I want another solution
//I get errors when running the codes // I get errors when running the codes // I get errors when running the codes //
# Import necessary libraries import pandas as pd from sklearn.model_selection import cross_val_score, train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest, f_classif from sklearn.decomposition import PCA from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, mean_absolute_error, mean_squared_error from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor from sklearn.naive_bayes import MultinomialNB from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor from sklearn.svm import SVC from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler import time
# Load your dataset (replace 'your_dataset.csv' with your actual dataset) # Also, replace 'text_column', 'target', and 'score' with your actual column names df = pd.read_csv('fake_news_dataset.csv')
# Define the features and labels X = df['text_column'] y_class = df['target'] y_reg = df['score']
# Split the dataset into training and testing sets X_train, X_test, y_class_train, y_class_test = train_test_split(X, y_class, test_size=0.2, random_state=42) X_train_reg, X_test_reg, y_reg_train, y_reg_test = train_test_split(X, y_reg, test_size=0.2, random_state=42)
# TF-IDF Vectorization tfidf_vectorizer = TfidfVectorizer(stop_words='english', max_features=5000) X_train_tfidf = tfidf_vectorizer.fit_transform(X_train) X_test_tfidf = tfidf_vectorizer.transform(X_test)
# Classification algorithms classifiers = { 'KNN(TF-IDF)': KNeighborsClassifier(), 'Naive Bayes(TF-IDF)': MultinomialNB(), 'Decision Tree(TF-IDF)': DecisionTreeClassifier(), # Add more classifiers as needed }
# Regression algorithms regressors = { 'KNN Reg(TF-IDF)': KNeighborsRegressor(), 'Naive Bayes Reg(TF-IDF)': MultinomialNB(), # Naive Bayes can be used for regression as well 'Decision Tree Reg(TF-IDF)': DecisionTreeRegressor(), # Add more regressors as needed }
# Tables for storing results classification_results = pd.DataFrame(columns=['Method', 'Accuracy', 'F-measure', 'Precision', 'Recall', 'Training/Testing Time', 'Number of Features']) regression_results = pd.DataFrame(columns=['Method', 'MAE', 'RMSE', 'Number of Features', 'Training Time/Testing Time'])
# Function for cross-validation and result filling def evaluate_classifier(model, X, y, method_name): start_time = time.time() scores = cross_val_score(model, X, y, cv=5, scoring='accuracy') end_time = time.time() classification_results.loc[len(classification_results)] = [ method_name, scores.mean(), f1_score(y, model.predict(X), average='weighted'), precision_score(y, model.predict(X), average='weighted'), recall_score(y, model.predict(X), average='weighted'), end_time - start_time, X.shape[1] ]
def evaluate_regressor(model, X, y, method_name): start_time = time.time() model.fit(X, y) end_time = time.time() y_pred = model.predict(X) regression_results.loc[len(regression_results)] = [ method_name, mean_absolute_error(y, y_pred), mean_squared_error(y, y_pred, squared=False), X.shape[1], end_time - start_time ]
# Evaluation loop for classification algorithms for method, clf in classifiers.items(): model = make_pipeline(StandardScaler(), clf) evaluate_classifier(model, X_train_tfidf, y_class_train, method)
# Evaluation loop for regression algorithms for method, reg in regressors.items(): model = make_pipeline(StandardScaler(), reg) evaluate_regressor(model, X_train_tfidf, y_reg_train, method)
# Display results print("Classification Results:") display(classification_results)
print(" Regression Results:") display(regression_results)
//I get errors when running the codes // I get errors when running the codes // I get errors when running the codes //
This question is solved I want another solution
You need to code the project in Python language. Jupyter notebook should be used and a single code file with .ipynb extension should be passed. If your computer's processing capacity is not sufficient, it is recommended to use Google Colab.
Classifying News Texts
The aim is to detect real and fake news content shared through social media posts. In the dataset, "target" indicates whether the news is real or fake, while "score" represents the truth/fakeness score of the news. This score is a confidence score of how real the news is. 5 is the highest score and indicates that the news is definitely true. 1 is the lowest score. While a score of 1 indicates that the news is definitely fake, a score of 3 indicates that there is no full opinion on whether the news is fake or real. It means 50 percent fake and 50 percent real.
*In the project, KNN, Decision Tree, Nave Bayes and SVM classification algorithms will be used. At this stage, binary classification will be applied. *Linear Regression, KNN Regression and Decision Tree Regression will be used in the project. This In this section, "score" prediction will be made. * In the project, text pre-processing (stemming, stop) is used to obtain vectors of text data. words etc.) techniques, TF-IDF, n-gram approaches (most popular) will be used. * In the project, feature selection and feature extraction techniques will be used. any for FS You can choose the algorithm. * Training and test sets should be adjusted by applying 5-fold cross validation. final fertility The results must be the average of the 5-fold results. * According to the results of classification and regression algorithms, the following tables are must be filled. *Parameter adjustment should be made for the classification and regression-based algorithms used. and the good results obtained should be added to the table.
Table 1: Classification Results
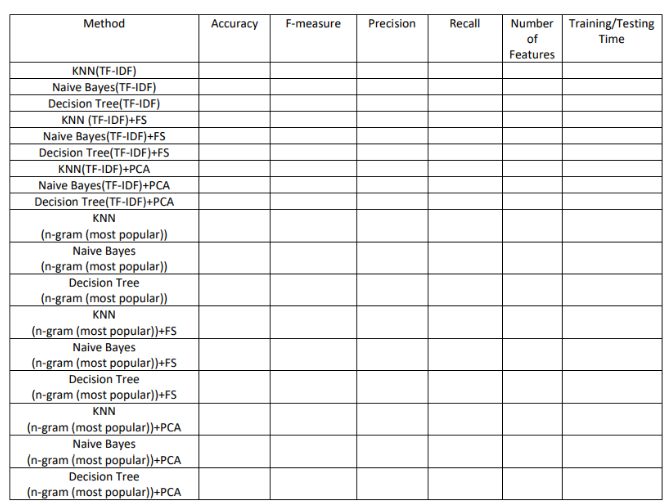
Table 2: Regression Results
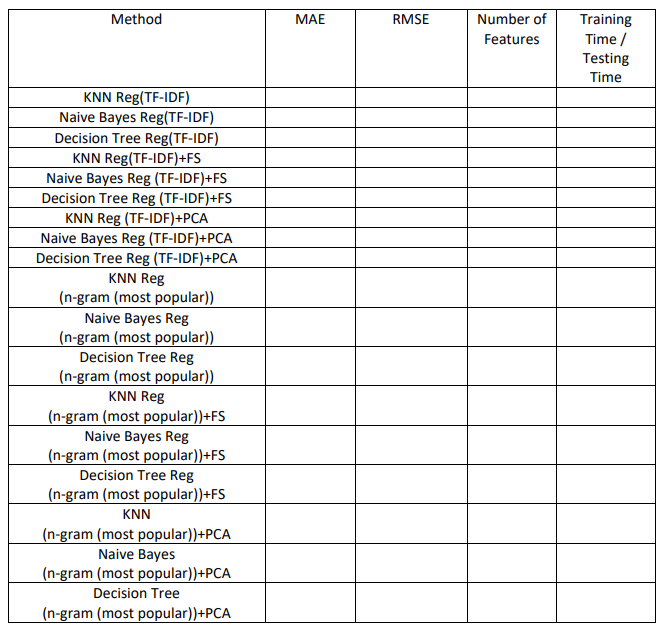
\begin{tabular}{|c|c|c|c|c|c|c|} \hline Method & Accuracy & F-measure & Precision & Recall & \begin{tabular}{c} Number \\ of \\ Features \end{tabular} & \begin{tabular}{c} Training/Testing \\ Time \end{tabular} \\ \hline \multicolumn{7}{|l|}{ KNN(TF-IDF) } \\ \hline \multicolumn{7}{|l|}{ Naive Bayes(TF-IDF) } \\ \hline \multicolumn{7}{|l|}{ Decision Tree(TF-IDF) } \\ \hline \multicolumn{7}{|l|}{ KNN (TF-IDF)+FS } \\ \hline \multicolumn{7}{|l|}{ Naive Bayes(TF-IDF)+FS } \\ \hline \multicolumn{7}{|l|}{ Decision Tree(TF-IDF)+FS } \\ \hline \multicolumn{7}{|l|}{ KNN(TF-IDF)+PCA } \\ \hline \multicolumn{7}{|l|}{ Naive Bayes(TF-IDF)+PCA } \\ \hline \multicolumn{7}{|l|}{ Decision Tree(TF-IDF)+PCA } \\ \hline \multicolumn{7}{|l|}{\begin{tabular}{c} KNN \\ (n-gram (most popular)) \end{tabular}} \\ \hline \multicolumn{7}{|l|}{\begin{tabular}{c} Naive Bayes \\ (n-gram (most popular)) \end{tabular}} \\ \hline \multicolumn{7}{|l|}{\begin{tabular}{c} Decision Tree \\ (n-gram (most popular)) \end{tabular}} \\ \hline \multicolumn{7}{|l|}{\begin{tabular}{c} KNN \\ (n-gram (most popular))+FS \end{tabular}} \\ \hline \multicolumn{7}{|l|}{\begin{tabular}{c} Naive Bayes \\ (n-gram (most popular))+FS \end{tabular}} \\ \hline \multicolumn{7}{|l|}{\begin{tabular}{c} Decision Tree \\ (n-gram (most popular))+FS \end{tabular}} \\ \hline \multicolumn{7}{|l|}{\begin{tabular}{c} KNN \\ (n-gram (most popular))+PCA \end{tabular}} \\ \hline \multicolumn{7}{|l|}{\begin{tabular}{c} Naive Bayes \\ (n-gram (most popular))+PCA \end{tabular}} \\ \hline \begin{tabular}{c} Decision Tree \\ (n-gram (most popular))+PCA \end{tabular} & & & & & & \\ \hline \end{tabular} \begin{tabular}{|c|c|c|c|c|} \hline Method & MAE & RMSE & \begin{tabular}{l} Number of \\ Features \end{tabular} & \begin{tabular}{c} Training \\ Time / \\ Testing \\ Time \end{tabular} \\ \hline \multicolumn{5}{|l|}{ KNN Reg(TF-IDF) } \\ \hline \multicolumn{5}{|l|}{ Naive Bayes Reg(TF-IDF) } \\ \hline \multicolumn{5}{|l|}{ Decision Tree Reg(TF-IDF) } \\ \hline \multicolumn{5}{|l|}{ KNN Reg(TF-IDF)+FS } \\ \hline \multicolumn{5}{|l|}{ Naive Bayes Reg (TF-IDF)+FS } \\ \hline \multicolumn{5}{|l|}{ Decision Tree Reg (TF-IDF)+FS } \\ \hline \multicolumn{5}{|l|}{ KNN Reg (TF-IDF)+PCA } \\ \hline \multicolumn{5}{|l|}{ Naive Bayes Reg (TF-IDF)+PCA } \\ \hline \multicolumn{5}{|l|}{ Decision Tree Reg (TF-IDF)+PCA } \\ \hline \multicolumn{5}{|l|}{\begin{tabular}{c} KNN Reg \\ (n-gram (most popular)) \\ \end{tabular}} \\ \hline \multicolumn{5}{|l|}{\begin{tabular}{c} Naive Bayes Reg \\ (n-gram (most popular)) \end{tabular}} \\ \hline \multicolumn{5}{|l|}{\begin{tabular}{c} Decision Tree Reg \\ (n-gram (most popular)) \\ \end{tabular}} \\ \hline \multicolumn{5}{|l|}{\begin{tabular}{c} KNN Reg \\ (n-gram (most popular))+FS \end{tabular}} \\ \hline \multicolumn{5}{|l|}{\begin{tabular}{c} Naive Bayes Reg \\ (n-gram (most popular))+FS \end{tabular}} \\ \hline \multicolumn{5}{|l|}{\begin{tabular}{c} Decision Tree Reg \\ (n-gram (most popular))+FS \end{tabular}} \\ \hline \multicolumn{5}{|l|}{\begin{tabular}{c} KNN \\ (n-gram (most popular))+PCA \end{tabular}} \\ \hline \multicolumn{5}{|l|}{\begin{tabular}{c} Naive Bayes \\ (n-gram (most popular))+PCA \end{tabular}} \\ \hline \begin{tabular}{c} Decision Tree \\ (n-gram (most popular))+PCA \end{tabular} & & & & \\ \hline \end{tabular}
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts