

Question: You work in a microfinance bank and are facing a problem around high default rates from customers. Your manager has given you data regarding past
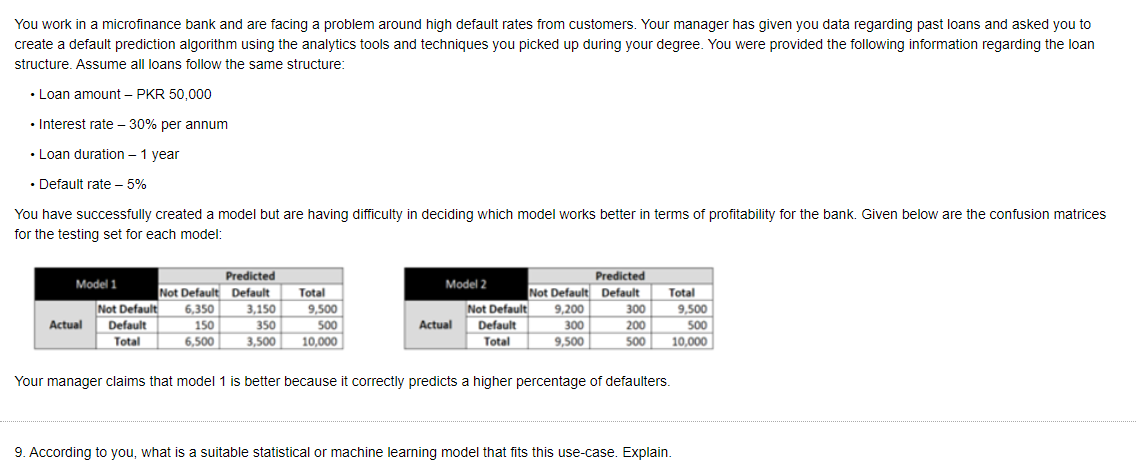
You work in a microfinance bank and are facing a problem around high default rates from customers. Your manager has given you data regarding past loans and asked you to create a default prediction algorithm using the analytics tools and techniques you picked up during your degree. You were provided the following information regarding the loan structure. Assume all loans follow the same structure: Loan amount - PKR 50,000 Interest rate - 30% per annum Loan duration - 1 year Default rate - 5% You have successfully created a model but are having difficulty in deciding which model works better in terms of profitability for the bank. Given below are the confusion matrices for the testing set for each model: Predicted Predicted Model 1 Total Not Default Default Total Not Default 6,350 3,150 9,500 Model 2 Not Default Default Not Default Default 9,200 300 300 9,500 Actual 150 350 500 Actual 200 500 Default Total 6,500 3,500 10,000 Total 9,500 500 10,000 Your manager claims that model 1 is better because it correctly predicts a higher percentage of defaulters. 9. According to you, what is a suitable statistical or machine learning model that fits this use-case. Explain. You work in a microfinance bank and are facing a problem around high default rates from customers. Your manager has given you data regarding past loans and asked you to create a default prediction algorithm using the analytics tools and techniques you picked up during your degree. You were provided the following information regarding the loan structure. Assume all loans follow the same structure: Loan amount - PKR 50,000 Interest rate - 30% per annum Loan duration - 1 year Default rate - 5% You have successfully created a model but are having difficulty in deciding which model works better in terms of profitability for the bank. Given below are the confusion matrices for the testing set for each model: Predicted Predicted Model 1 Total Not Default Default Total Not Default 6,350 3,150 9,500 Model 2 Not Default Default Not Default Default 9,200 300 300 9,500 Actual 150 350 500 Actual 200 500 Default Total 6,500 3,500 10,000 Total 9,500 500 10,000 Your manager claims that model 1 is better because it correctly predicts a higher percentage of defaulters. 9. According to you, what is a suitable statistical or machine learning model that fits this use-case. Explain
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts