

Question: Unadulterated Abstract Base Class Project. Characterize a class considered BasicShape which will be an unadulterated unique class. The class will have one safeguarded information part
Unadulterated Abstract Base Class Project. Characterize a class considered BasicShape which will be an unadulterated unique class. The class will have one safeguarded information part that will be a twofold called region. It will give a capacity called.getArea which ought to return the worth of the information part region. It will likewise give a capacity called calcArea which should be an unadulterated virtual capacity.
Characterize a class called Circle. It ought to be a determined class of the BasicShape class. This class will have 3 private information individuals. It will have 2 long whole number information individuals called centerX and centery. The last information part is a twofold called range. It will have a constructor that acknowledges values for centerX, centery and sweep. This ought to call the superseded calcArea capacity of this class. This class characterizes its rendition of the calcArea work which decides the region of the circle utilizing the equation region = 3.14159* radius* sweep. The class will likewise give two capacities called getCenterX and getCenterY which return the right qualities.
Characterize a class called Rectangle. It ought to be a determined class of the BasicShape class. This class will have 2 private information individuals called width and length. The two information individuals ought to be long numbers. Its constructor will have boundaries for both the width and length. It will likewise abrogate the calcArea work. For this class the calcArea capacity will utilize the equation region = length width. It will give part work called getWidth and getLength which ought to return the right qualities.
In principle make examples of the Circle and Rectangle classes. It ought to then show the region of the two shapes utilizing a capacity characterized as In this task we proceed with our examination of executing "grouping" ADTs. This week, it will be re-executed utilizing a connected rundown. Peruse Chapter 4 cautiously and particularly ensure that you read Section 4.5, pages 232-238 (225-231, third ed.) which explicitly express how to carry out Sequence with connected records. We will execute ParticleSeq which has a marginally unique point of interaction (attach rather than addBefore and addAfter), yet with the same information structure suggested in the reading material. Utilize this connect to acknowledge the task: https://classroom.github.com/a/Zjjz-o9t 1 Concerning Implementation of ParticleSeq The ParticleSeq class will have similar public statements as the ParticleSeq you imple- mented previously (aside from no real way to indicate an underlying limit), yet the information structure (private fields) will be totally unique. Announce a hub class as a "private static class" inside the ParticleSeq class. Such a class (one announced inside another class) is known as a "settled" class. The hub class ought to have two fields: the information (of type Particle) and the following hub. It ought to have a constructor however no different techniques. In spite of what it says in the course book, try not to compose techniques in the "Hub" class. The plan in the course reading beginning on page 232 (225, third ed.) has overt repetitiveness in it. This implies you should actually take a look at additional things in wellFormed. We have various tests to ensure that this is finished. In the event that you don't grasp the test, and you have perused the clarification of the fields in the course reading, if it's not too much trouble, post an inquiry on Piazza about the test. The overt repetitiveness makes specific tasks simpler (particularly ones that don't change anything, like isCurrent), however muddles crafted by those which make changes (such as removeCurrent). The money saving advantage analytics varies per project, however for your data, we don't think about the course book plan ideal: the tail pointer specifically is convoluted to stay up with the latest and has basically no advantage. It is a helpful activity, notwithstanding, to see what occurs in the event that we keep it. Dissimilar to in the past task, clone requires some (troublesome!) work for you to do: the list should be replicated, cell by cell, and pointers of the clone made to highlight the suitable replicated hubs. 1.1 The Invariant The invariant is more mind boggling than in the past execution. It has the accompanying parts: 1. The rundown may exclude a cycle, where the following connection of some hub guides back toward some previous hub.
CS 351: Data Structures and Algorithms Homework #4 2. The tail pointer should highlight the last hub in the rundown, yet on the off chance that the rundown is vacant, the tail pointer is invalid. 3. The forerunner field is either invalid or focuses to a hub in the rundown, other than the tail. It can't highlight a hub that is as of now not in the rundown ? the hub should be reachable from the top of the rundown. It additionally can't highlight the last hub in the rundown (might you at any point see the reason why?). 4. The cursor should be invalid or the primary hub assuming the forerunner is invalid, and generally should be the hub after the forerunner. 5. The field manyNodes ought to precisely address the quantity of hubs in the rundown. We have carried out the initial segment for you; you ought to carry out different parts yourself. You ought to do this from the get-go in fostering the execution ? it will assist you with getting bugs as fast as could really be expected. We give code to test the invariant checker. Be extremely cautious that you never change any fields in the invariant checker, wellFormed. It is ONLY expected to check the invariant and return valid or bogus (with a report). It ought to never change things. 2 Files The storehouse homework4.git incorporates the accompanying records: src/TestParticleSeq.java Updated usefulness tests. src/TestParticleSeq.java Unchanged productivity tests. src/TestInvariant.java Call out to the invariant checker tests. src/edu/uwm/cs351/ParticleSeq.java Skeleton document. lib/homework4.jar JAR document containing the other ADTs, and irregular testing. This undertaking additionally has arbitrary testing. It is carried out without change from Homework #2 in light of the fact that the public point of interaction (and importance of the strategies) for the ParticleSeq class is unaltered.
1. Compose a C program that makes a two-layered cluster. This 2D cluster populates 100 components with irregular upsides of x and y for every component. After you make the cluster, compose a different capacity to print out the 100 components on the terminal and call this capacity before you leave the program. If it's not too much trouble, NOTE: X, Y are float values (two digit accuracy) and ought to ONLY go from [-2, 2]
2. Utilize the past C program. Add another capacity to make 5 new exhibits, every one of them has 20 components with two irregular upsides of x and y. These 20 components are chosen arbitrarily from the first 2D exhibit in Q1 with no overt repetitiveness between components across all clusters. After you make the 5 new exhibits, compose a different capacity to print out the components in each cluster on the terminal and call this capacity before you leave the program.
3. Utilize the past C program. Use pointers to sort all components in each cluster in climbing request in light of their wellness values (F),
27591443 Compose a different capacity to print out the initial 8 components in each cluster and their relating wellness values on the terminal and call this capacity before you leave the program.
4. Utilize the past C program. Compose another capacity to observe the component that addresses the best arrangement (yields the base wellness esteem F) across all clusters and save it in a different exhibit with the name brilliant frog. Then, at that point, print out the upsides of X and Y of this component alongside the relating wellness esteem.
5. Utilize the past C program. Compose another capacity to move the initial 8 components (frogs) from every single one of the 5 exhibits to the next 4 clusters (2 to each). After you complete the rearranging, change the worth of Y in all components in all exhibits to an alternate irregular worth among 2 and - 2. Rehash steps (3 - 5) 100 times and update the golden_frog component assuming you tracked down a new golden_frog that gives an improved outcome (least wellness esteem (F)). Print the last golden_frog on the terminal.
Extra guidelines from the understudy: The comparing test yield for each progression is given underneath.
Stage 1 Output: Illustration of the result: P001 = 0.22, 1.62 P002 = 1.32, - 0.44 ...... P100 = - 1.78, 0.99
Stage 2 Output: Illustration of the result: Exhibit 1 - P01 = 0.22, 1.62 Exhibit 1 - P02 = 1.32, - 0.44 ...... Exhibit 5 - P20 = - 1.78, 0.99
Stage 3 Output: Illustration of the result: Exhibit 1 - P01 = 0.22, 1.62 , F = 0.17 Exhibit 1 - P02 = 1.32, - 0.44 , F = 0.59 ......
Stage 4 Output: Illustration of the result: Brilliant Frog: X=1, Y=-1 ... Wellness Value = - 0.94
Stage 5 Output: Illustration of the result: Brilliant Frog: X=1, Y=-1 ... Wellness Value = - 0.94
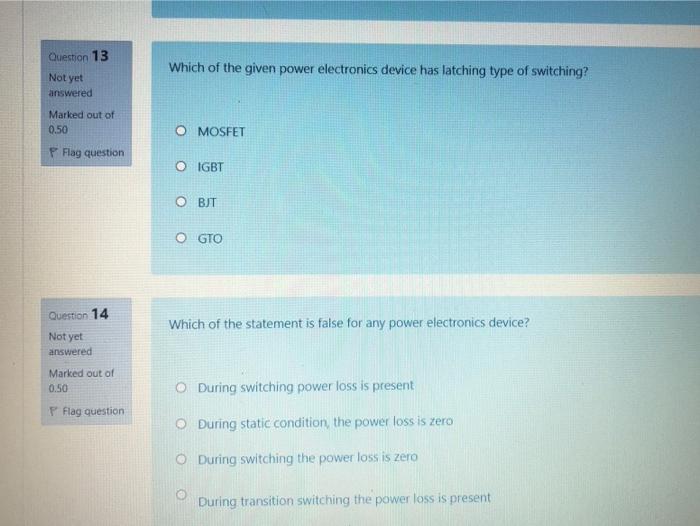

Question 13 Not yet answered Marked out of 0.50 P Flag question Question 14 Not yet answered Marked out of 0.50 P Flag question Which of the given power electronics device has latching type of switching? O MOSFET O IGBT OBJT O GTO Which of the statement is false for any power electronics device? O During switching power loss is present O During static condition, the power loss is zero O During switching the power loss is zero During transition switching the power loss is present
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts