

Question: We are given a python file which loops through each dimension D = [1, 2, 5, 10, 20, 50, 200, 1000], and creates a data
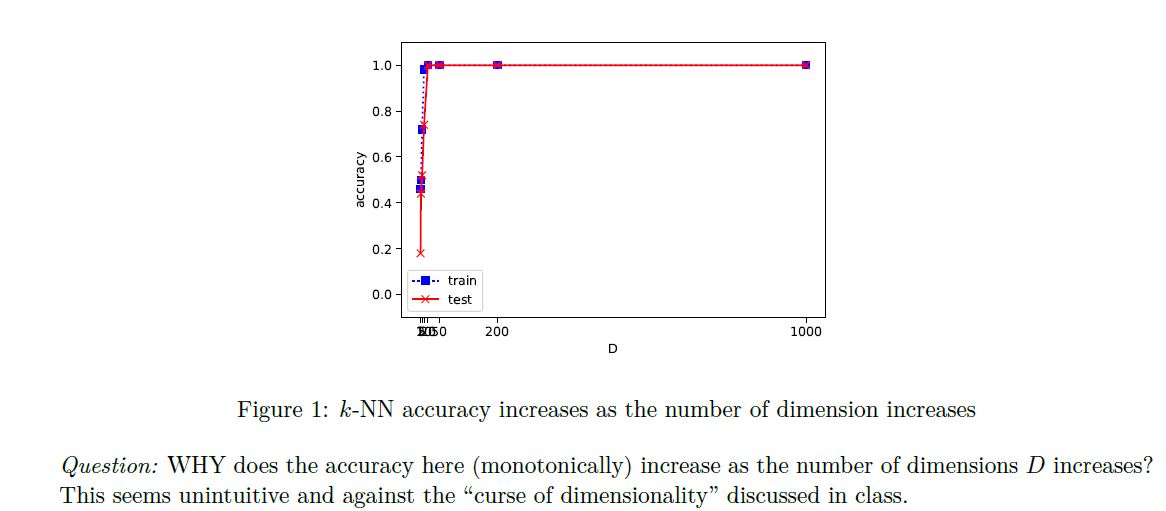
We are given a python file which loops through each dimension D = [1, 2, 5, 10, 20, 50, 200, 1000], and creates a data set using the following command:
X, y = make_blobs(n_samples=n_points, centers=6, n_features=D, cluster_std=5, random_state=42)
The script then splits the data and evaluates it with KNN producing the image above.
The question asked is then: WHY does the accuracy here (monotonically) increase as the number of dimensions D increases? This seems unintuitive and against the curse of dimensionality discussed in class.
Figure 1: k-NN accuracy increases as the number of dimension increases Question: WHY does the accuracy here (monotonically) increase as the number of dimensions D increases? This seems unintuitive and against the "curse of dimensionality" discussed in class
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts