

Question: treasure1.txt The Old Sea-dog at the Admiral Benbow SQUIRE TRELAWNEY, Dr Livesey, and the rest of these gentlemen having asked me to write down the
treasure1.txt
The Old Sea-dog at the Admiral Benbow
SQUIRE TRELAWNEY, Dr Livesey, and the rest of these gentlemen having asked me to write down the whole particulars about Treasure Island, from the beginning to the end, keeping nothing back but the bearings of the island, and that only because there is still treasure not yet lifted, I take up my pen in the year of grace 17__ and go back to the time when my father kept the Admiral Benbow inn and the brown old seaman with the sabre cut first took up his lodging under our roof.
frankenstein1.txt
I am by birth a Genevese, and my family is one of the most distinguished of that republic. My ancestors had been for many years counsellors and syndics, and my father had filled several public situations with honour and reputation. He was respected by all who knew him for his integrity and indefatigable attention to public business. He passed his younger days perpetually occupied by the affairs of his country; a variety of circumstances had prevented his marrying early, nor was it until the decline of life that he became a husband and the father of a family.
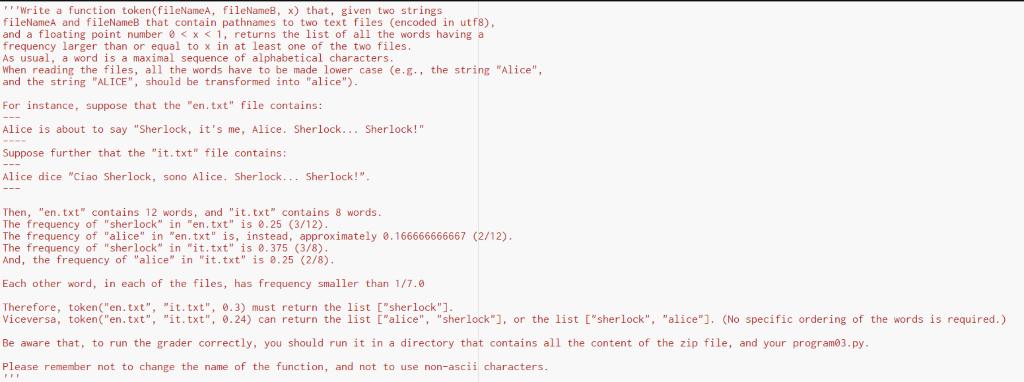
**"Write a function token(fileNameA, fileNameB, x) that, given two strings fileNameA and fileNameB that contain pathnames to two text files (encoded in utf8), and a floating point number e < x < 1, returns the list of all the words having a frequency larger than or equal to x in at least one of the two files. As usual, a word is a maximal sequence of alphabetical characters. When reading the files, al1 the words have to be made lower case (e.g., the string "Alice", and the string "ALICE", should be transformed into "alice"). For instance, suppose that the "en. txt" file contains: --- Alice is about to say "Sherlock, it's me, Alice. Sherlock... Sherlock!" Suppose further that the "it.txt" file contains: --- Alice dice "Ciao Sherlock, sono Alice, Sherlock... Sherlock!". --- Then, "en. txt" contains 12 words, and "it.txt" contains 8 words. The frequency of "sherlock" in "en. txt" is 0.25 (3/12). The frequency of "alice" in "en. txt" is, instead, approximately 0.166666666667 (2/12). The frequency of "sherlock" in "it. txt" is 0.375 (3/8). And, the frequency of "alice" in "it.txt" is 0.25 (2/8). Each other word, in each of the files, has frequency smaller than 1/7.0 Therefore, token("en.txt", "it. txt", 0.3) must return the list ["sherlock"]. Viceversa, token("en. txt", "it. txt", 0.24) can return the list ["alice", "sherlock"), or the list ["sherlock", "alice"]. (No specific ordering of the words is required.) Be aware that, to run the grader correctly, you should run it in a directory that contains all the content of the zip file, and your program03.py. Please remember not to change the name of the function, and not to use non-ascii characters.
Step by Step Solution
3.33 Rating (144 Votes )
There are 3 Steps involved in it
def wordcountstrfor char in str strreplacechar str strlowercounts dictwords strsplittotalcount0for w... View full answer

Get step-by-step solutions from verified subject matter experts