

Question: Write a scientific paper about Next Word Prediction Model Deep Learning and Python The scientific paper should be contain: Abstract: keywords: Introduction: Materials &Methods: Results:
Write a scientific paper about Next Word
Prediction Model Deep Learning and
Python
The scientific paper should be contain:
Abstract: keywords:
Introduction:
Materials &Methods:
Results: Put the proportions from the pictures below
Discussion:
Referen:

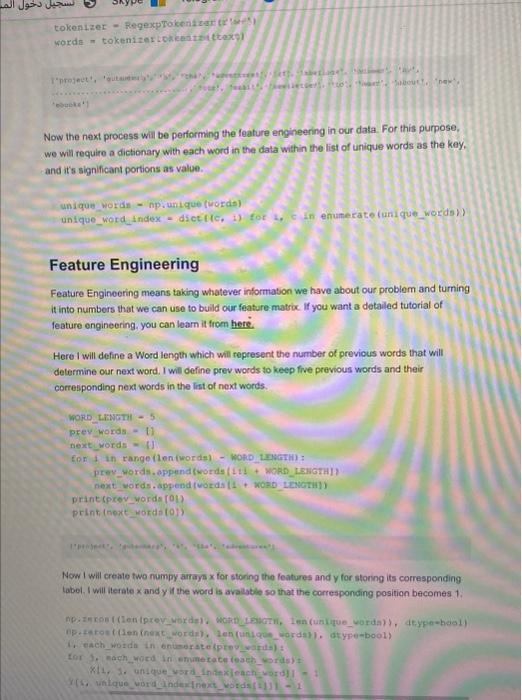


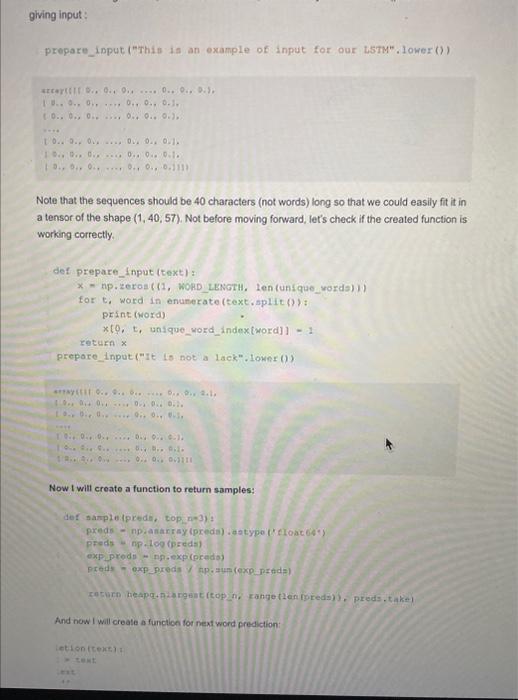
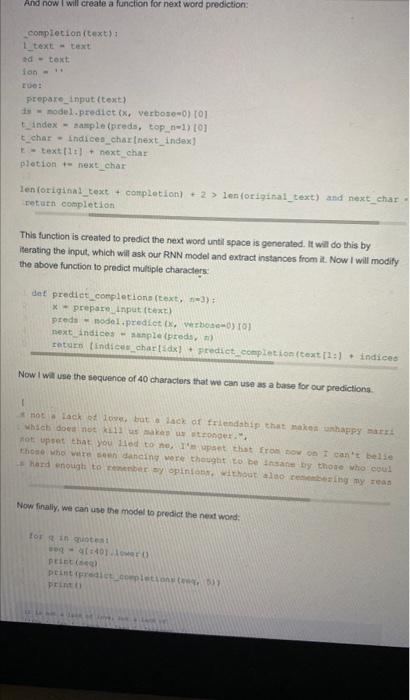
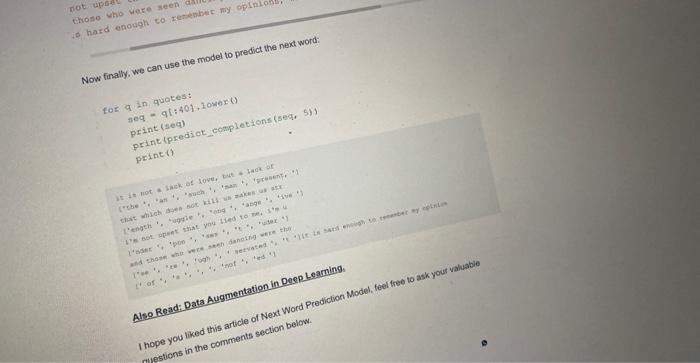
Most of the keyboards in smartphones give next word prediction features: google also uses next word prediction based on our browsing history, So a preloaded data is also stored in the keyboard function of our smartphones to predict the next word correcty. In this article. I will train a Deep Learning model for next word prediction using Python. I will use the Tensorflow and Keras library in Python for next word prodiction model. For making a Next Word Prediction model, I will train a Recurtent Neural Network (RNN). So let's start with this task now without wasting any time. Also. Read - 100+ Machine Learning Projects Solved and Explained, Next Word Prediction Model To start with our next word prediction model, lets import some all the lioraries we need for this task Inpore numpy as np from nttk.tokenize inpore Regexproconlzor fron keras.models import sequential, 1opalmodel rren keras. layera imore Lsms troh keras. Mayers.oore inport pense. Activation fton kecas. optimizers inport pusprop Inipore matplotilib.pyplot ap ple import plakio inipert heapg As I told earlier, Google uses our browsing history to make noxt word predictions, smartphones, and all the keyboards that are trained to predict the next word are trained using spme data. Sol will also use a dataset. You can downioad the dataset from here. Now lets load the data and have a quick look at what we are going to work with: path=1662-0.txttext=open(gath)-read().Howerti)printfcorpae2ength:.len(text)). corpus length: 581887 Now I will split the dataset into each word in order but without the presence of some special characters. tokenizer = ReqexpTokenidest trtyeit) sorde m tokenites Lomeetitaitiexpl Now the next process will be performing the feature engineering in our data. For this purpose, we will require a dictionary with each word in the data within the list of unique words as the kay. and it 5 significant portions as value. unique wordn - np.unique (irords) unique_word_index = dict ((c,,1) for 2,in enumerate (unique_words)) Feature Engineering Feature Engineering means taking whatever information we have about our problem and tuming it into numbors that we can use to build our feature matrix. If you want a detailed tutorial of feature engineering, you can learn it from here. Here I will define a Word length which will represent the number of previous words that will determine our next word. I will define prev words to keep five previous words and their cortesponding next words in the list of next words. Now I will create two numpy arrays x for storing the features and y for storing its corresponding: tabel. I wil iterate x and y if the word is avallathe so that the corresponding position becomes 1. Bp.zeros ( ( Ien (next worde). Ien (untque_orda) . dtyre-bool) Hr each woddo in onumarate (preq-waruts) a tor 3. Fach word in enumetace (each_writs) t Xi1. 1. undque wsradinitex)each wotd I =1 Now before moving forward, have a look at a single sequence of words: print (x[0][0]) [False False False ... False False False] Building the Recurrent Neural network As I stated earlier, I will use the Recurrent Neural networks for next word prediction model. Here I will use the LSTM model, which is a very powerful RNN. model - Sequential () mode1. add (LSTM(1.28, input_shape-(Wort_LzadTH, len (unique_words) )) model. add (Dense (len (unique worde) )) mode1. add (Act ivation (' softrax')) Training the Next Word Prediction Model I will be training the next word prediction model with 20 epochs: optinizer - pusprop (1r=0.01) moded. conpile (Loas"' cateqorical_crossentropy", optimizerpoptindzer. n hiatory = model.fit (X,Y, validation_aplit-0,05, batch_size-126, epoc Now we have successfully trained our model, before moving forward to evaluating our model, it will be better to save this model for our future use. nodel. save ("keras_next_word_model., 5 ) plckle.dunp (history, open ("history. p,mb) ) model - Load model ('Keran next wordinodwh. hs') hiatory = plokle. load (open ("hintary,p*, "rb"l) Evaluating the Next Word Prediction Model Now lers have a quick look at how our model is going to behave based on its accuracy and loss changes while training: Dit.plot chantaty I Raco"ld pleplac (histery plevel.acevi) plt. titled ('moidet securacy' plt.plot (history ('loss'l) plt.plot (historyl'val loss'1) plt.title ('model(loss') plt.ylabel ('losa') plt.xlabel ('epoch') plt.legend (l'trasn', 'test'), logu' upper left') Testing Next Word Prediction Model Now ler's buld a python program to predict the next word using our trained model. For this, I will define some essentlai functions that will be used in the process. dist propere input (cexti: x. - npzzerot (11, sxoumice Leviori, len (ehars) ) for th. that in enunerate (text). xid. it. inder_indiced ( char 11=1. return x Now before moving forward, leris test the function, make surs you use a lower0 function while giving input: giving input: prepare_input ("This is an example of input for our L5TM". Lomer ()) stcoruIrt.,0.90.2..0.00.,0.511..0.0,0,0,0,0,0.1,t0.,0.,0......0.,0.,0.7.t0..0.,0.,....0.0.,0.,0.1.1t.,8.,0.,...0..0.0.0.1.10.,0..0......0.0.0.0.111 Note that the sequences should be 40 characters (not words) long so that we could easily fit it in a tensor of the shape (1,40,57). Not before moving forward, let's check if the created function is working correctly. \[ \begin{array}{l} \text { def prepare_Input (text): } \\ x \text { = } n p \text {. zeroe ( } 11 \text {, WORD_LENGTH, Len (unique_vords) 1) } \\ \text { for } 6 \text {. word in enunerate (text. split ()): } \\ \text { print (woxd) } \\ x[0, t \text {, unique_word_index }[\text { word }]]=1 \\ \text { return } x \\ \text { prepare input ("It is noti a lack", lower ()) } \\ \end{array} \] Now t will create a function to return samples: desanple(prede,top.pe3):preds-npianarray(preda).aetypo(celoac6s")predswnp.100(preds)exppredy-np.exp(predo)preds=expgredsyAp,aup(expprende)FoturnheapquAiargent(topzh,Eange(2enBoreda)),preds,take1 And now I wall create a function for next word prediction: ietion (texe] it tent This function is created to predict the next word unti space is generated. It will do this by Ilerating the input, which will ask our RNN model and extract instances from it. Now I will modify the above function to predict multiple characters: det predict_corpletions (text, n=3} f x - prepare input (text) Preda - nodel.predice (x, verboae-0) (0) next indices - aunple (preds, h) return (indices_char {ddx}+ predict_ecoplecion (text [1:=1 + indiceo Now I wile use the sequence of 40 characters that we can use as a base for cur predictions. 1 a noci 4 lack et fove but io 2ack of frlendahip that makes unhappy =arrt wbseb doeat not kili us aukes ur etropget. ". 7ot upeet that you Hed to no, I'm iapset that froslinovion I can't helie thoie who wite saen dahcing vore thought ro be Insant by thote who coul Now finally, we can use the model to predict the next word: Lor 8 in quintest apq-qtz401.Hower1prict(aed) peint ffredlek_-gopptelponi. Now finally, we can use the model to predict the next word: torqinquotestseq-q(:401+10oser()print(seq)print(prediotcompletions(seq,s)) prine () Also Read: Data Augnentation in Desp Learning: Inope you liked this article of Next Word Prediction Nodel, teel tree to ask your valuble avestions in the comments section below
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts