

Question: Write the third function (unique_regions) in python and please provide the flowchart of how the function works. the function should take the list the was
Write the third function (unique_regions) in python and please provide the flowchart of how the function works. the function should take the list the was created in first function from the input file txt that I provided in the end of this post and then it should return the continents as a list.
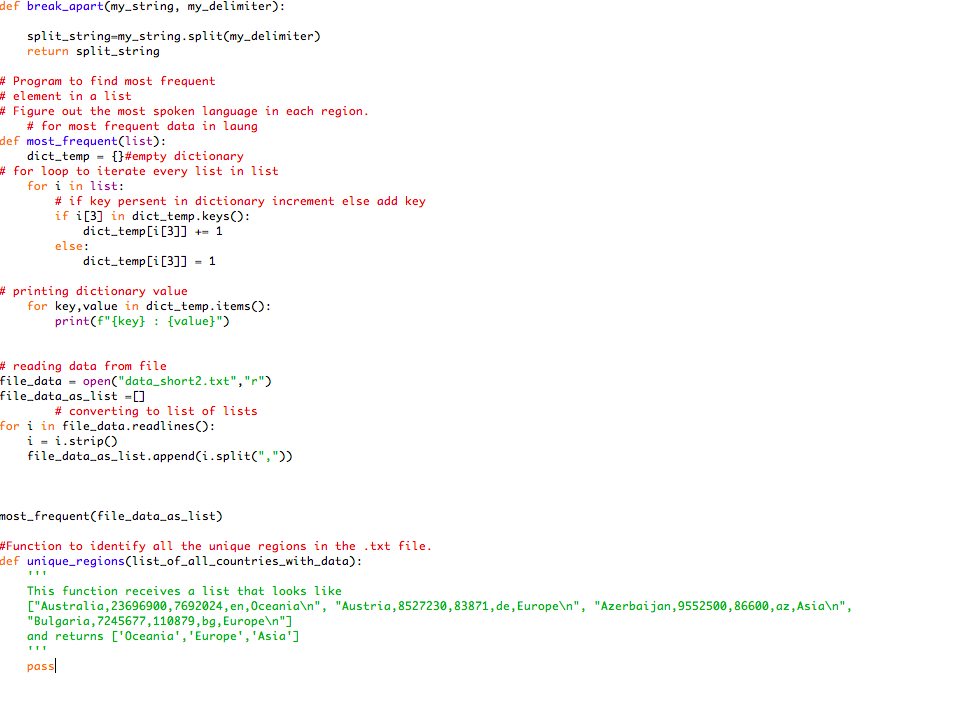
def break_apart(my_string, my_delimiter): split_string=my_string.split(my_delimiter) return split_string
# Program to find most frequent # element in a list # Figure out the most spoken language in each region. # for most frequent data in laung def most_frequent(list): dict_temp = {}#empty dictionary # for loop to iterate every list in list for i in list: # if key persent in dictionary increment else add key if i[3] in dict_temp.keys(): dict_temp[i[3]] += 1 else: dict_temp[i[3]] = 1
# printing dictionary value for key,value in dict_temp.items(): print(f"{key} : {value}")
# reading data from file file_data = open("data_short2.txt","r") file_data_as_list =[] # converting to list of lists for i in file_data.readlines(): i = i.strip() file_data_as_list.append(i.split(","))
most_frequent(file_data_as_list)
#Function to identify all the unique regions in the .txt file. def unique_regions(list_of_all_countries_with_data): ''' This function receives a list that looks like ["Australia,23696900,7692024,en,Oceania ", "Austria,8527230,83871,de,Europe ", "Azerbaijan,9552500,86600,az,Asia ", "Bulgaria,7245677,110879,bg,Europe "] and returns ['Oceania','Europe','Asia'] ''' pass
the input txt file :
Latvia,1991800,64559,lv,Europe South Sudan,11384393,619745,en,Africa Egypt,87668100,1002450,ar,Africa Guinea-Bissau,1746000,36125,pt,Africa Zimbabwe,13061239,390757,en,Africa Mali,15768000,1240192,fr,Africa Portugal,10477800,92090,pt,Europe New Zealand,4547900,270467,en,Oceania Croatia,4267558,56594,hr,Europe Nauru,10084,21,en,Oceania Estonia,1315819,45227,et,Europe Libya,6253000,1759540,ar,Africa Sierra Leone,6205000,71740,en,Africa Denmark,5655750,43094,da,Europe Tuvalu,11323,26,en,Oceania Chad,13211000,1284000,fr,Africa Tonga,103252,747,en,Oceania Niger,17138707,1267000,fr,Africa Benin,9988068,112622,fr,Africa Penguin Land,0,14200000,penguin_language,Antarctica
def break_apart(my_string, my_delimiter): split_string=my_string.split(my_delimiter) return split_string # Program to find most frequent # element in a list # Figure out the most spoken language in each region. # for most frequent data in laung def most frequent(list): dict_temp = {}#empty dictionary # for loop to iterate every list in list for i in list: # if key persent in dictionary increment else add key if i [3] in dict_temp. keys(): dict_temp[i [3]] +- 1 else: dict_temp[i[3]] = 1 # printing dictionary value for key, value in dict_temp.items(): print("{key} : {value}") # reading data from file file_data = open("data_short2.txt","r") file_data_as_list = [] # converting to list of lists for i in file_data.readlines(): i - i.strip) file_data_as_list.append(i.split(","> most frequent(file_data_as_list) #Function to identify all the unique regions in the .txt file. def unique_regions(list_of_all_countries_with_data): This function receives a list that looks like ["Australia, 23696900,7692024, en, Oceania ", "Austria, 8527230,83871, de, Europe ", "Azerbaijan, 9552500, 86600, az, Asia ", "Bulgaria, 7245677,110879, bg, Europe "] and returns ['Oceania', 'Europe', 'Asia'] pass
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts