

Question: A k-zigzag network has k Boolean root variables and k + 1 Boolean leaf variables, where root i is connected to leaves i and i
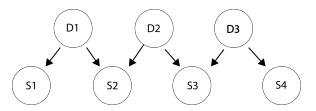
A k-zigzag network has k Boolean root variables and k + 1 Boolean leaf variables, where root i is connected to leaves i and i + 1. Figure S13.52 shows an example for k = 3, where each Di represents a Boolean disease variable and each Sj is a Boolean symptom variable.
a. Does having symptom S4 affect the probability of disease D1? Why or why not?
b. Using only conditional probabilities from the model, express the probability of having symptom S1 but not symptom S2, given disease D1.
c. Can exact inference in a k-zigzag net can be done in time O(k)? Explain.
d. Suppose the values of all the symptom variables have been observed, and you would like to do Gibbs sampling on the disease variables (i.e., sample each variable given its Markov blanket). What is the largest number of non-evidence variables that have to be considered when sampling any particular disease variable? Explain your answer.
e. Suppose k = 50. You would like to run Gibbs sampling for 1 million samples. Is it a good idea to precompute all the sampling distributions, so that when generating each individual sample no arithmetic operations are needed? Explain.
f. A k-zigzag++ network is a k-zigzag network with two extra variables: one is a root connected to all the leaves and one is a leaf to which all the roots are connected. You would like to run Gibbs sampling for 1 million samples in a 50-zigzag++ network. Is it a good idea to precompute all the sampling distributions? Explain.
g. Returning to the k-zigzag network, let us assume that in every case the values of all symptom and disease variables are observed. This means that we can consider training a neural net to predict diseases from symptoms directly (rather than using a Bayes net and probabilistic inference), where the symptoms are inputs to the neural net and the diseases are the outputs. The issue is the internal connectivity of the neural net: to which diseases should the symptoms be connected? A neural-net expert opines that we can simply reverse the arrows in the figure, so that D1 is predicted only as a function f1(S1, S2) and so on (The functions fi will be learned from data, but the representation of fi and the learning algorithm is not relevant here.) The reasoning is that argues that because D1 doesn’t affect S3 and S4, they are not needed for predicting D1. Is the expert right? Explain.
Figure S13.52
$1 5 D1 $2 D2 $3 D3 54
Step by Step Solution
3.35 Rating (161 Votes )
There are 3 Steps involved in it
a No D 1 is independent of its nondescendants including S 4 given its parents empty set ie D 1 is ab... View full answer

Get step-by-step solutions from verified subject matter experts