

A tree-augmented Naive Bayes model (TANB) is identical to a Naive Bayes model, except the features are
Question:
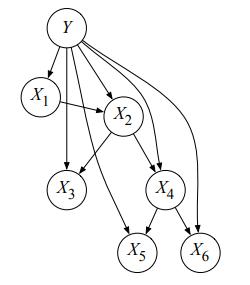
A tree-augmented Naive Bayes model (TANB) is identical to a Naive Bayes model, except the features are no longer assumed conditionally independent given the class Y. Specifically, if (X1, X2, . . . , Xn) are the observable features, a TANB allows X1, . . . , Xn to be in a tree-structured Bayes net in addition to having Y as a parent. An example is given in Figure S13.40:
a. Suppose we observe no variables as evidence in the TANB above. What is the classification rule for the TANB? Write the formula in terms of the conditional distributions in the TANB.
b. Assume we observe all the variables X1 = x1, X2 = x2, . . . , X6 = x6 in the TANB above. Write the classification rule for the TANBin terms of the conditional distributions.
c. Specify an elimination order that is efficient for variable elimination applied to the query P(Y | X5 = x5) in the TANB above (the query variable Y should not be included your ordering). How many variables are in the biggest factor (there may be more than one; if so, list only one of the largest) induced by variable elimination with your ordering? Which variables are they?
d. Specify an elimination order that is efficient for the query P(X3 | X5 = x5) in the TANB above (including X3 in your ordering). How many variables are in the biggest factor (there may be more than one; if so, list only one of the largest) induced by variable elimination with your ordering? Which variables are they?
e. Does it make sense to run Gibbs sampling to do inference in a TANB? In two or fewer sentences, justify your answer.
Figure S13.40
Step by Step Answer:
a The solution is simply the maximal y according to the prior probabilities of y argmax y Py b We wa...View the full answer



Artificial Intelligence A Modern Approach
ISBN: 9780134610993
4th Edition
Authors: Stuart Russell, Peter Norvig
