

a. Please indicate if the following statements are true or false. (i) Let A be the set
Question:
a. Please indicate if the following statements are true or false.
(i) Let A be the set of all actions and S the set of states for some MDP. Assuming that |A| << |S|, one iteration of value iteration is generally faster than one iteration of policy iteration that solves a linear system during policy evaluation.
(ii) For any MDP, changing the discount factor does not affect the optimal policy for the MDP. The following problem will take place in various instances of a grid world MDP. Shaded cells represent walls. In all states, the agent has available actions ↑, ↓, ←, →.
Performing an action that would transition to an invalid state (outside the grid or into a wall) results in the agent remaining in its original state. In states with an arrow coming out, the agent has an additional action EXIT. In the event that the EXIT action is taken, the agent receives the labeled reward and ends the game in the terminal state T. Unless otherwise stated, all other transitions receive no reward, and all transitions are deterministic.
For all parts of the problem, assume that value iteration begins with all states initialized to zero, i.e., V0(s) = 0 ∀s. Let the discount factor be γ = 1/2 for all following parts.
b. Suppose that we are performing value iteration on the grid world MDP in Figure S17.3.
(i) What’s the optimal values for A and B?
(ii) After how many iterations k will we have Vk(s) = V∗ (s) for all states s? If it never occurs, write “never”.
(iii) Suppose that we wanted to re-design the reward function. For which of the following new reward functions would the optimal policy remain unchanged? Let R(s, a, s') be the original reward function.
(I) R1(s, a, s') = 10R(s, a, s')
(II) R2(s, a, s') = 1 + R(s, a, s')
(III) R3(s, a, s') = R(s, a, s') 2
(IV) R4(s, a, s') = −1
(V) None
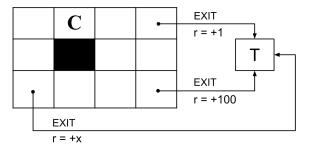
c. For the problem in Figure S17.4, we add a new state in which we can take the EXIT action with a reward of +x.
(i) For what values of x is it guaranteed that our optimal policy π∗ has π∗ (C) = ←?
(ii) For what values of x does value iteration take the minimum number of iterations k to converge to V∗ for all states? Write ∞ and −∞ if there is no upper or lower bound, respectively.
(iii) Fill the box with value k, the minimum number of iterations until Vk has converged to V∗ for all states.
Figure S17.3
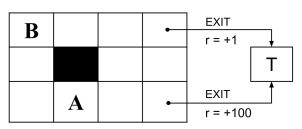
Figure S17.4
Step by Step Answer:
a Fill out the following TrueFalse questions i True One iteration of value iteration is OS 2 A where...View the full answer



Artificial Intelligence A Modern Approach
ISBN: 9780134610993
4th Edition
Authors: Stuart Russell, Peter Norvig
