

Question: Convert your code from Exercise 4.6 into PTX code. How many instructions are needed for the kernel? Exercise 4.6 With CUDA we can use coarse-grain
Convert your code from Exercise 4.6 into PTX code. How many instructions are needed for the kernel?
Exercise 4.6
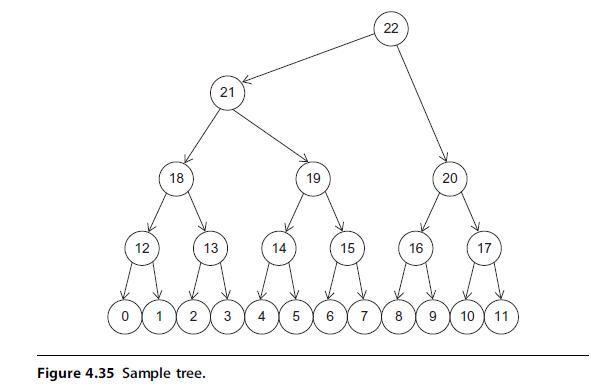
With CUDA we can use coarse-grain parallelism at the block level to compute the conditional likelihood of multiple nodes in parallel. Assume that we want to compute the conditional likelihood from the bottom of the tree up. Assume seq_length = = 500 for all notes and that the group of tables for each of the 12 leaf nodes is stored in consecutive memory locations in the order of node number (e.g., the mth element of clP on node n is at clP [n*4*seq_length+m*4]). Assume that we want to compute the conditional likelihood for nodes 12–17, as shown in Figure 4.35. Change the method by which you compute the array indices in your answer from Exercise 4.5 to include the block number.
Exercise 4.5
Now assume we want to implement the MrBayes kernel on a GPU using a single thread block. Rewrite the C code of the kernel using CUDA.
Assume that pointers to the conditional likelihood and transition probability tables are specified as parameters to the kernel. Invoke one thread for each iteration of the loop. Load any reused values into shared memory before performing operations on it.
12 18 13 21 2 3 Figure 4.35 Sample tree. 14 5 19 6 15 22 16 20 17 10 11
Step by Step Solution
3.37 Rating (147 Votes )
There are 3 Steps involved in it
The question provided appears to be part of a larger context where specific CUDA code was developed probably in a book or courses exercises As you hav... View full answer

Get step-by-step solutions from verified subject matter experts