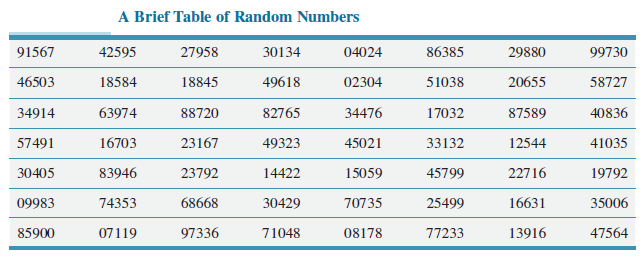
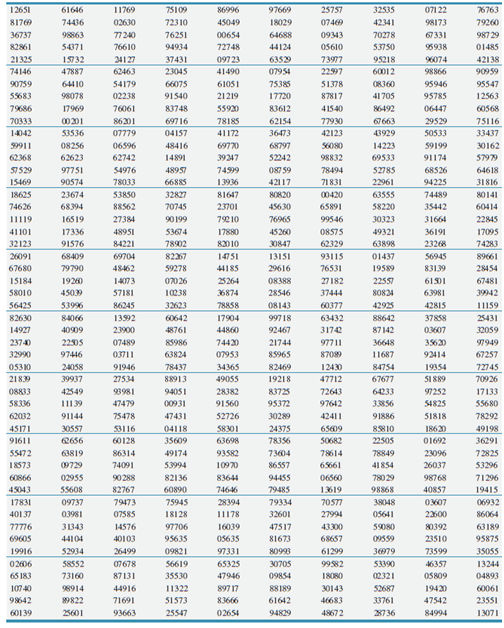
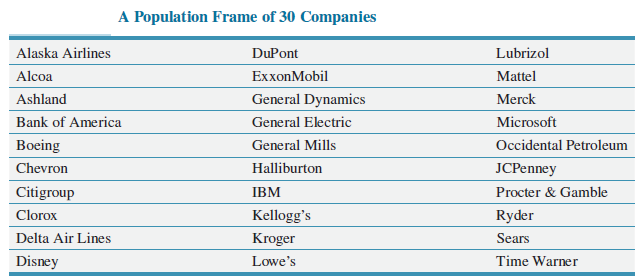
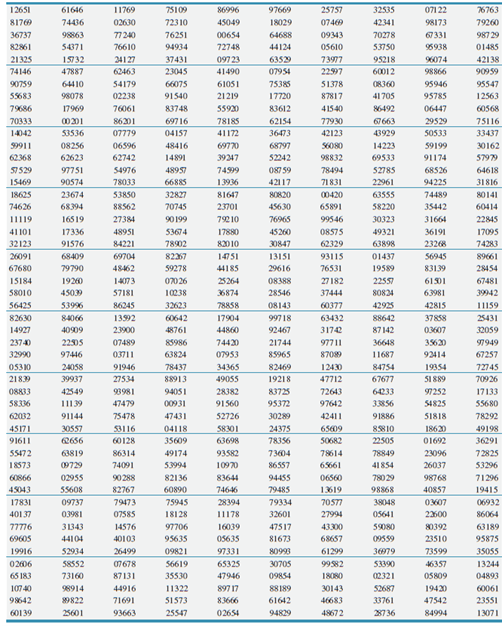
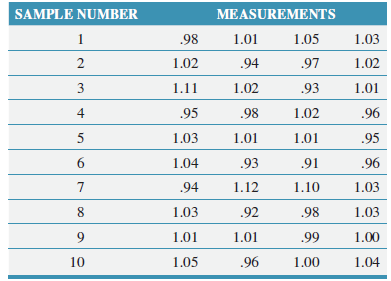
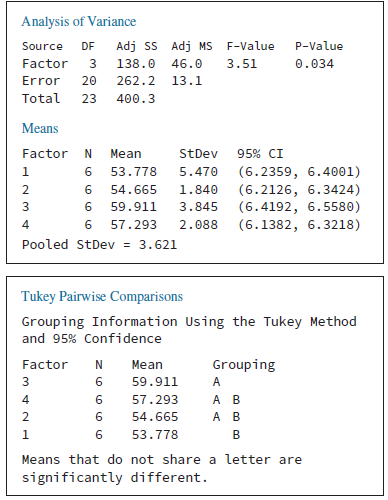
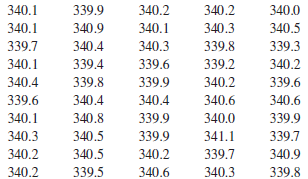
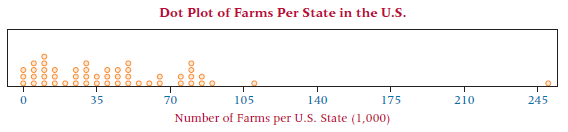
Business Statistics For Contemporary Decision Making 9th edition Ken Black - Solutions
Unlock the full potential of your studies with "Business Statistics For Contemporary Decision Making, 9th Edition" by Ken Black. Our comprehensive online resources offer an extensive answers key and solution manual, providing detailed solutions in PDF format. Access solved problems for every chapter, complete with step-by-step answers that make understanding complex concepts easier than ever. Our questions and answers guide, along with the test bank, ensures you're well-prepared for any test. Benefit from the instructor manual and textbook solutions, all available for free download. Elevate your learning experience with these invaluable resources today!