

Question: Return to the variant of PCA examined in Exercise 11.2. Using a (possibly synthetic) data set of your choice, compare the classical PCA and the
Return to the variant of PCA examined in Exercise 11.2. Using a (possibly synthetic) data set of your choice, compare the classical PCA and the variant examined here, especially in terms of its sensitivity to outliers. Make sure to establish an evaluation protocol that is as rigorous as possible. Discuss your results.
Data from exercise 11.2:
Let X = [x1,...., xm] ∈ Rn,m. For p = 1, 2, we consider the problem
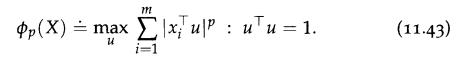
If the data is centered, the case p = 1 amounts to finding a direction of largest "deviation" from the origin, where deviation is measured using the ℓi-norm; arguably, this is less sensitive to outliers than the case p = 2, which corresponds to principal component analysis.
Step by Step Solution
3.34 Rating (157 Votes )
There are 3 Steps involved in it
Generate or Obtain Data Create a dataset with synthetic data or use an appropriate realworld dataset Make sure it has a significant number of outliers ... View full answer

Get step-by-step solutions from verified subject matter experts