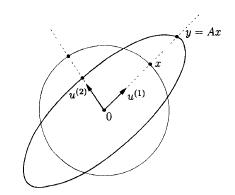
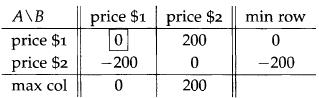
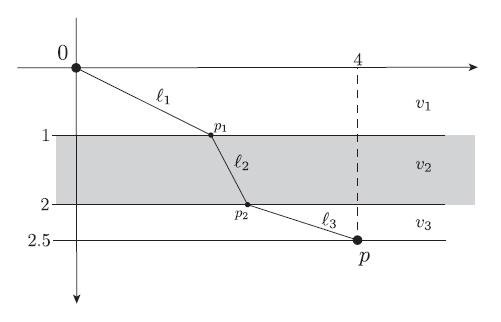
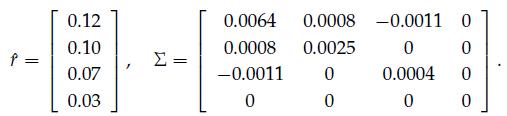
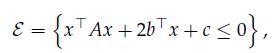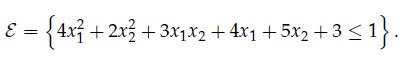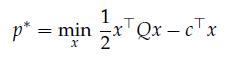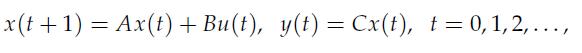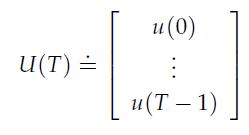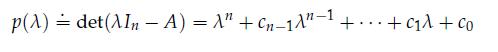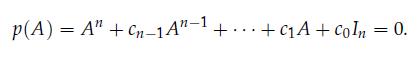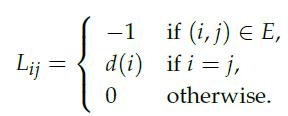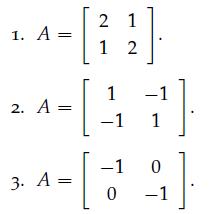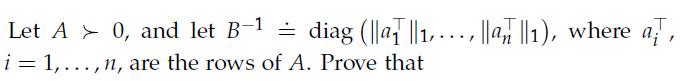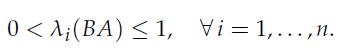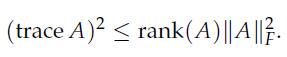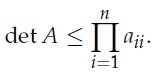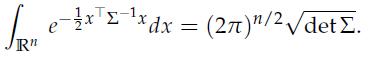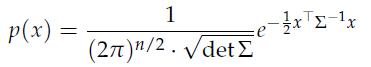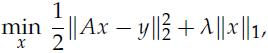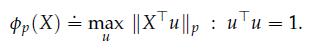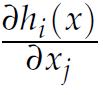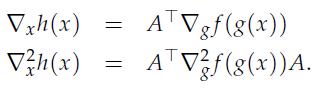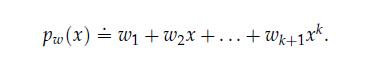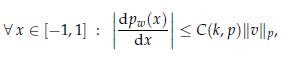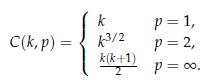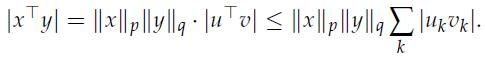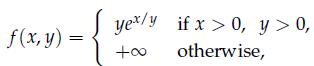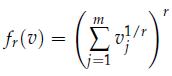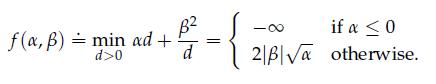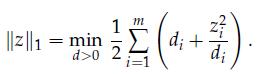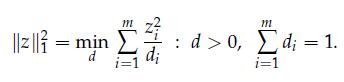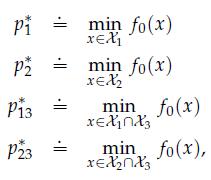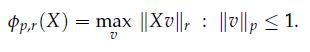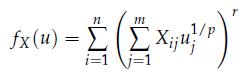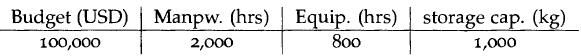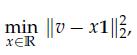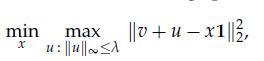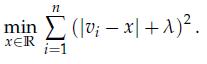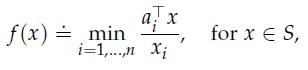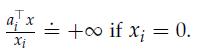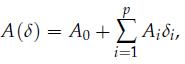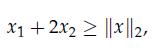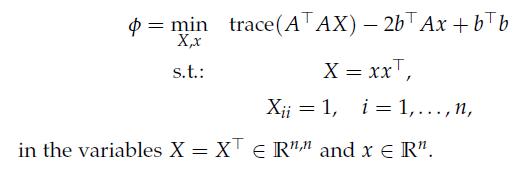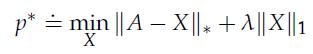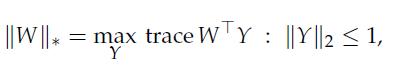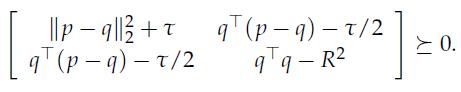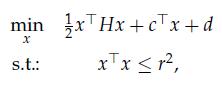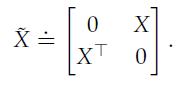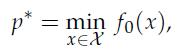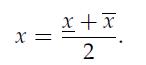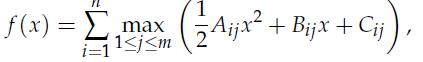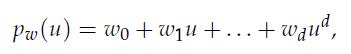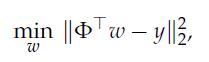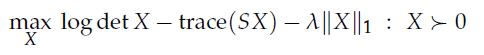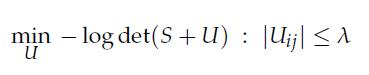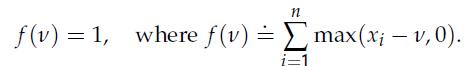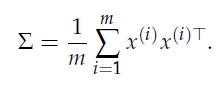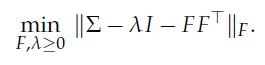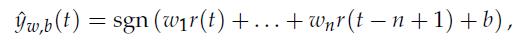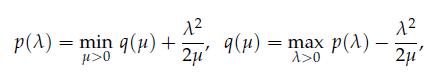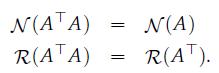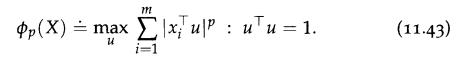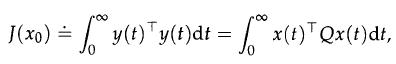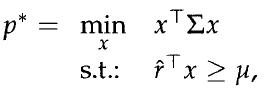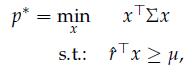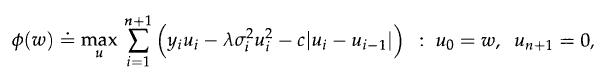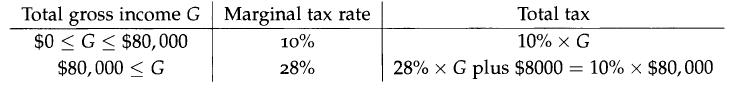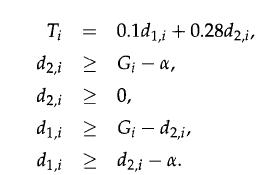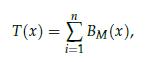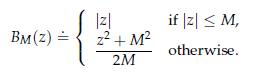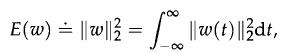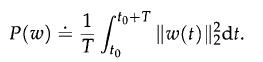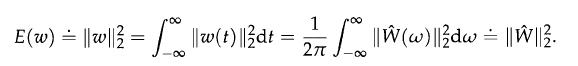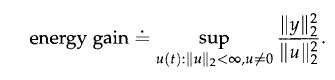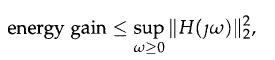Optimization Models 1st Edition Giuseppe C. Calafiore, Laurent El Ghaoui - Solutions
Explore comprehensive solutions and answers to the "Optimization Models" textbook by Giuseppe C. Calafiore and Laurent El Ghaoui. Access our online answer key for step-by-step answers and solved problems. Our solutions manual and chapter solutions provide detailed insights, perfect for students and instructors alike. Enhance your learning with our test bank and instructor manual, offering a wealth of questions and answers. Download solutions in PDF format for free and enjoy easy access to textbook solutions anytime. Whether you’re preparing for exams or seeking a deeper understanding, our resources are your go-to guide for mastering optimization models.