

How many training instances are in the dataset? How many test instances? How many features are...
Fantastic news! We've Found the answer you've been seeking!
Question:

Transcribed Image Text:
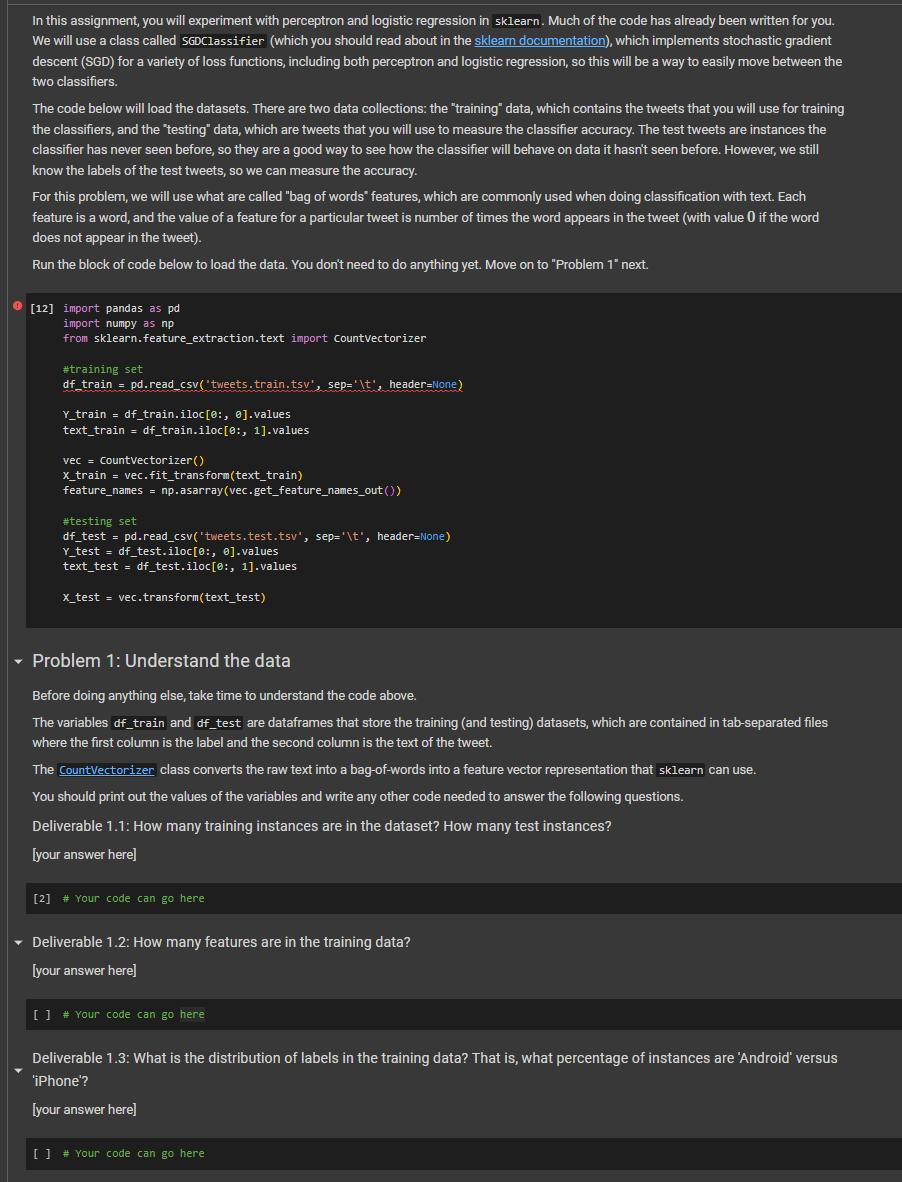
How many training instances are in the dataset? How many test instances? How many features are in the training data? What is the distribution of labels in the training data? That is, what percentage of instances are 'Android' versus 'iPhone'? Assignment overview In this assignment, you will build a classifier that tries to infer whether tweets from @realDonaldTrump were written by Trump himself or by a staff person. This is an example of binary classification on a text dataset. It is known that Donald Trump uses an Android phone, and it has been observed that some of his tweets come from Android while others come from other devices (most commonly iPhone). It is widely believed that Android tweets are written by Trump himself, while iPhone tweets are written by other staff. For more information, you can read this blog post by David Robinson, written prior to the 2016 election, which finds a number of differences in the style and timing of tweets published under these two devices. (Some tweets are written from other devices, but for simplicity the dataset for this assignment is restricted to these two.) This is a classification task known as "authorship attribution", which is the task of inferring the author of a document when the authorship is unknown. We will see how accurately this can be done with linear classifiers using word features. In this assignment, you will experiment with perceptron and logistic regression in sklearn. Much of the code has already been written for you. We will use a class called SGDClassifier (which you should read about in the sklearn documentation), which implements stochastic gradient descent (SGD) for a variety of loss functions, including both perceptron and logistic regression, so this will be a way to easily move between the two classifiers. The code below will load the datasets. There are two data collections: the "training" data, which contains the tweets that you will use for training the classifiers, and the "testing" data, which are tweets that you will use to measure the classifier accuracy. The test tweets are instances the classifier has never seen before, so they are a good way to see how the classifier will behave on data it hasn't seen before. However, we still know the labels of the test tweets, so we can measure the accuracy. For this problem, we will use what are called "bag of words" features, which are commonly used when doing classification with text. Each feature is a word, and the value of a feature for a particular tweet is number of times the word appears in the tweet (with value 0 if the word does not appear in the tweet). Run the block of code below to load the data. You don't need to do anything yet. Move on to "Problem 1" next. [12] import pandas as pd import numpy as np from sklearn.feature_extraction.text import countVectorizer #training set df_train = pd.read_csv('tweets.train.tsv', sep='\t', header=None) Y_train = df_train.iloc[0, 0].values text_train = df_train.iloc[0:, 1].values vec = CountVectorizer() x_train = vec.fit_transform(text_train) feature_names = np.asarray(vec.get_feature_names_out()) #testing set df_test = pd.read_csv('tweets.test.tsv', sep='\t', header=None) Y_test = df_test.iloc[0:, 0].values text_test = df_test.iloc[0:, 1].values x_test = vec.transform(text_test) Problem 1: Understand the data Before doing anything else, take time to understand the code above. The variables df_train and df_test are dataframes that store the training (and testing) datasets, which are contained in tab-separated files where the first column is the label and the second column is the text of the tweet. The CountVectorizer class converts the raw text into a bag-of-words into a feature vector representation that sklearn can use. You should print out the values of the variables and write any other code needed to answer the following questions. Deliverable 1.1: How many training instances are in the dataset? How many test instances? [your answer here] [2] # Your code can go here Deliverable 1.2: How many features are in the training data? [your answer here] [ ] # Your code can go here Deliverable 1.3: What is the distribution of labels in the training data? That is, what percentage of instances are 'Android' versus 'iPhone'? [your answer here] [ ] # Your code can go here How many training instances are in the dataset? How many test instances? How many features are in the training data? What is the distribution of labels in the training data? That is, what percentage of instances are 'Android' versus 'iPhone'? Assignment overview In this assignment, you will build a classifier that tries to infer whether tweets from @realDonaldTrump were written by Trump himself or by a staff person. This is an example of binary classification on a text dataset. It is known that Donald Trump uses an Android phone, and it has been observed that some of his tweets come from Android while others come from other devices (most commonly iPhone). It is widely believed that Android tweets are written by Trump himself, while iPhone tweets are written by other staff. For more information, you can read this blog post by David Robinson, written prior to the 2016 election, which finds a number of differences in the style and timing of tweets published under these two devices. (Some tweets are written from other devices, but for simplicity the dataset for this assignment is restricted to these two.) This is a classification task known as "authorship attribution", which is the task of inferring the author of a document when the authorship is unknown. We will see how accurately this can be done with linear classifiers using word features. In this assignment, you will experiment with perceptron and logistic regression in sklearn. Much of the code has already been written for you. We will use a class called SGDClassifier (which you should read about in the sklearn documentation), which implements stochastic gradient descent (SGD) for a variety of loss functions, including both perceptron and logistic regression, so this will be a way to easily move between the two classifiers. The code below will load the datasets. There are two data collections: the "training" data, which contains the tweets that you will use for training the classifiers, and the "testing" data, which are tweets that you will use to measure the classifier accuracy. The test tweets are instances the classifier has never seen before, so they are a good way to see how the classifier will behave on data it hasn't seen before. However, we still know the labels of the test tweets, so we can measure the accuracy. For this problem, we will use what are called "bag of words" features, which are commonly used when doing classification with text. Each feature is a word, and the value of a feature for a particular tweet is number of times the word appears in the tweet (with value 0 if the word does not appear in the tweet). Run the block of code below to load the data. You don't need to do anything yet. Move on to "Problem 1" next. [12] import pandas as pd import numpy as np from sklearn.feature_extraction.text import countVectorizer #training set df_train = pd.read_csv('tweets.train.tsv', sep='\t', header=None) Y_train = df_train.iloc[0, 0].values text_train = df_train.iloc[0:, 1].values vec = CountVectorizer() x_train = vec.fit_transform(text_train) feature_names = np.asarray(vec.get_feature_names_out()) #testing set df_test = pd.read_csv('tweets.test.tsv', sep='\t', header=None) Y_test = df_test.iloc[0:, 0].values text_test = df_test.iloc[0:, 1].values x_test = vec.transform(text_test) Problem 1: Understand the data Before doing anything else, take time to understand the code above. The variables df_train and df_test are dataframes that store the training (and testing) datasets, which are contained in tab-separated files where the first column is the label and the second column is the text of the tweet. The CountVectorizer class converts the raw text into a bag-of-words into a feature vector representation that sklearn can use. You should print out the values of the variables and write any other code needed to answer the following questions. Deliverable 1.1: How many training instances are in the dataset? How many test instances? [your answer here] [2] # Your code can go here Deliverable 1.2: How many features are in the training data? [your answer here] [ ] # Your code can go here Deliverable 1.3: What is the distribution of labels in the training data? That is, what percentage of instances are 'Android' versus 'iPhone'? [your answer here] [ ] # Your code can go here
Expert Answer:

Related Book For 

Machine Learning For Business Analytics
ISBN: 9781119828792
1st Edition
Authors: Galit Shmueli, Peter C. Bruce, Amit V. Deokar, Nitin R. Patel
Posted Date:
Students also viewed these databases questions
-
Case 2 Consumers Take a Shine to Apple, Inc.* Synopsis: Few companies have been able to master the arts of product innovation, a "cool" brand image, and customer evangelism like Apple. After nearly...
-
Write a memo to an employee whose work and behavior have been unsatisfactory. (You are the department manager.) Try to motivate the employee to improve his performance. Be brief, direct, honestand as...
-
Repeat Exercise 13 for the integral In Exercise 13 Determine the values of n and h required to approximate To within 105 and compute the approximation. Use a. Composite Trapezoidal rule. b. Composite...
-
An investor wishes to buy euros spot (at $1.3908) and sell euros forward for 180 days (at $1.3996). Is there any premium on 180-day Euro or is there any discount on 180-day forward? Show your workings
-
The figure below shows the results of a survey in which 1000 adults were asked how much they spend in preparation for personal travel each year. Make a frequency distribution for the data. Then use...
-
In Eastwood Co., capital balances are Irey $40,000 and Pedigo $50,000. The partners share income equally. Vernon is admitted to the firm with a 45% interest by an investment of cash of $58,000....
-
Suppose a point charge creates a 1 2 5 0 0 N / C electric field at a distance of 0 . 3 5 m . What is the magnitude of the point charge in coulombs? What is the strength of the field, in newtons per...
-
ERD Problems Given the following business rules, create the appropriate Crow's Foot ERD. (10 points) a. A company operates many departments. b. Each department employs one or more employees. C. Each...
-
How accurate are companies with their estimates (guesses)? Isn't estimating bad debts a way of manipulating net income? How does a company keep control on these estimates?
-
What financial information should be used to determine whether the decision to crossover into cloud computing is acceptable or should be rejected?
-
What transaction do you create in QBO to take advantage of the discount and reduce the amount you pay?
-
What type of municipal bond pay interest that is typically taxable? What type of municipal bond pay interest that is typically taxable?
-
Explain why the auditor needs to know how to conduct a risk assessment. Why does the auditor need to know how to conduct a risk assessment?
-
Read the case study "Memories and Culture"' and respond to one (1) of the following discussion topics: Describe two (2) examples of your own flashbulb memories. Use Brown and Kuliks theory to explain...
-
What are three disadvantages of using the direct write-off method?
-
While the BohrSommerfeld condition sometimes gets the energy eigenvalues exactly correct, it can also be used for systems where the exact solution is not known. In this example, we will estimate the...
-
It's useful to see how our quantum perturbation theory works in a case that we can solve exactly. Let's consider a two-state system in which the Hamiltonian is...
-
Let's see how the variational method works in another application. Let's assume we didn't know the ground-state energy of the quantum harmonic oscillator and use the variational method to determine...

Study smarter with the SolutionInn App