

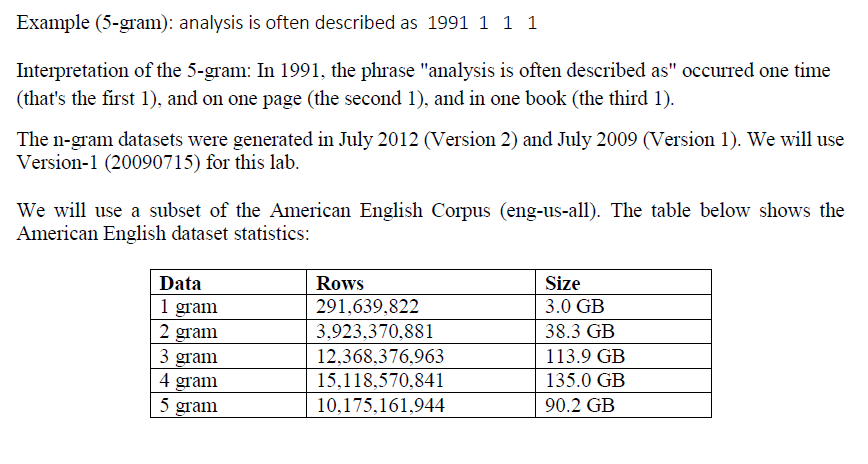
Question: --------------------------------------------------------------------------------------- #mrex1.py ''' Implement a MapReduce program that computes the most popular bigram (2-gram) of all time in the dataset (as determined by the count

![_, line): data=line.split('\t') ngram = data[0].strip() year = data[1].strip() count = data[2].strip()](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2024/09/66f2f8c2093ee_42566f2f8c19789d.jpg)
---------------------------------------------------------------------------------------
#mrex1.py
'''
Implement a MapReduce program that computes the most popular bigram (2-gram) of all time in
the dataset (as determined by the count field).
'''
from mrjob.job import MRJob
class MyMRJob(MRJob):
def mapper(self, _, line):
data=line.split('\t')
ngram = data[0].strip()
year = data[1].strip()
count = data[2].strip()
pages = data[3].strip()
books = data[4].strip()
#Emit key-value pairs where key is ngram+year and value is count of ngram
yield ngram+year, int(count)
def reducer(self, key, list_of_values):
# Send all (count, ngram+year) pairs to the same reducer.
# So we can easily use Python's max() function.
yield None, (sum(list_of_values),key)
def reducer2(self, _, list_of_values):
# Reducer-2 get input tuples as follows:
# None, [(212, cloud computing 2006), (156, mobile phones 2003)]
# max function will yield tuple with max value of the count
yield max(list_of_values)
def steps(self):
return [self.mr(mapper=self.mapper, reducer=self.reducer), self.mr(reducer=self.reducer2)]
if __name__ == '__main__':
MyMRJob.run()
-----------------------------------------------------------------------------------
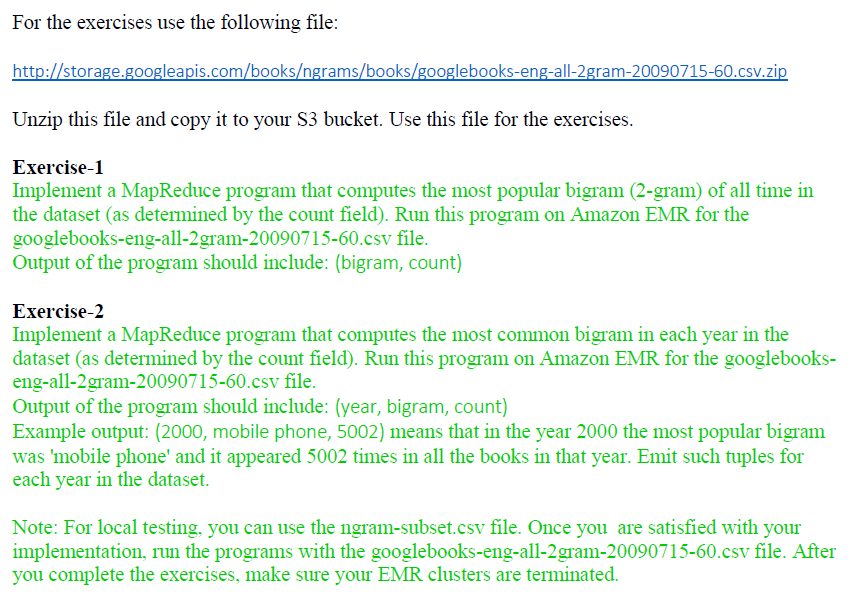
#mrex2.py
""" Implement a MapReduce program that computes the most common bigram in each year in the dataset (as determined by the count field). Output of the program should include: (year, bigram, count) Example output: (2001, mobile phone, 5002) means that in the year 2001 the most popular bigram was 'mobile phone' and it appeared 5002 times in all the books in that year. Emit such tuples for each year in the dataset.
"""
from mrjob.job import MRJob
class MyMRJob(MRJob): def mapper(self, _, line): data=line.split('\t') ngram = data[0].strip() year = data[1].strip() count = data[2].strip() yield year, (int(count),ngram)
def reducer(self, key, list_of_values): yield key, max(list_of_values) if __name__ == '__main__': MyMRJob.run()
--------------------------------------------------------------------------------
#mrjob.conf
runners: emr: aws_access_key_id: aws_secret_access_key: ec2_key_pair: mykeypair ec2_key_pair_file: /home/ubuntu/mykeypair.pem ssh_tunnel_to_job_tracker: true ec2_instance_type: m3.xlarge num_ec2_instances: 1
Problem 2 - MapReduce for analyzing Google n-gram Dataset Google n-gram dataset which is a freely-available collection of n-grams (fixed size tuples of words) extracted from the Google Books corpus. The n specifies the number of elements in the tuple, so a 5- gram contains five words The n-grams in this dataset were produced by passing a sliding window over the text of books and outputting a record for each new token. For example for the line - 'Python is a high level language' The 2-grams will be (Python, is) (is, a) (a, high) (high, level) (level, language) Format Each row of data contains 1) n-gram itself 2) year in which the n-gram appeared 3) number of times the n-gram appeared in the books from the corresponding year (count) 4) number of pages on which the n-gram appeared in this year (page-count) 5) number of distinct books in which the n-gram appeared in this year (book count) Problem 2 - MapReduce for analyzing Google n-gram Dataset Google n-gram dataset which is a freely-available collection of n-grams (fixed size tuples of words) extracted from the Google Books corpus. The n specifies the number of elements in the tuple, so a 5- gram contains five words The n-grams in this dataset were produced by passing a sliding window over the text of books and outputting a record for each new token. For example for the line - 'Python is a high level language' The 2-grams will be (Python, is) (is, a) (a, high) (high, level) (level, language) Format Each row of data contains 1) n-gram itself 2) year in which the n-gram appeared 3) number of times the n-gram appeared in the books from the corresponding year (count) 4) number of pages on which the n-gram appeared in this year (page-count) 5) number of distinct books in which the n-gram appeared in this year (book count)
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts