

Question: Need help with this problem, can anyone help please ? Consider the MDP shown below. It has 6 states and 4 actions. As shown on
Need help with this problem, can anyone help please ?
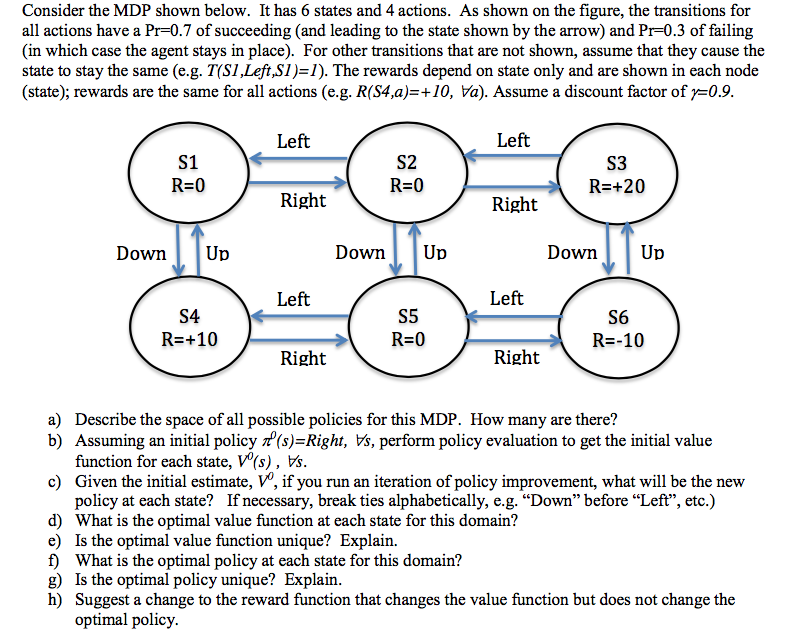
Consider the MDP shown below. It has 6 states and 4 actions. As shown on the figure, the transitions for all actions have a Pr = 0.7 of succeeding (and leading to the state shown by the arrow) and Pr = 0.3 of failing (in which case the agent stays in place). For other transitions that are not shown, assume that they cause the state to stay the same (e.g. T(S1, Left, S1) = 1). The rewards depend on state only and are shown in each node (state); rewards are the same for all actions (e.g. R(S4, a)= + 10, a). Assume a discount factor of gamma =0.9. Describe the space of all possible policies for this MDP. How many are there? Assuming an initial policy pi_0 (s)=Right, s, perform policy evaluation to get the initial value function for each state, V^0(s), s. Given the initial estimate, V^0, if you run an iteration of policy improvement, what will be the new policy at each state? If necessary, break ties alphabetically, e.g. "Down" before "Left", etc.) What is the optimal value function at each state for this domain? Is the optimal value function unique? Explain. What is the optimal policy at each state for this domain? Is the optimal policy unique? Explain. Suggest a change to the reward function that changes the value function but does not change the optimal policy. Consider the MDP shown below. It has 6 states and 4 actions. As shown on the figure, the transitions for all actions have a Pr = 0.7 of succeeding (and leading to the state shown by the arrow) and Pr = 0.3 of failing (in which case the agent stays in place). For other transitions that are not shown, assume that they cause the state to stay the same (e.g. T(S1, Left, S1) = 1). The rewards depend on state only and are shown in each node (state); rewards are the same for all actions (e.g. R(S4, a)= + 10, a). Assume a discount factor of gamma =0.9. Describe the space of all possible policies for this MDP. How many are there? Assuming an initial policy pi_0 (s)=Right, s, perform policy evaluation to get the initial value function for each state, V^0(s), s. Given the initial estimate, V^0, if you run an iteration of policy improvement, what will be the new policy at each state? If necessary, break ties alphabetically, e.g. "Down" before "Left", etc.) What is the optimal value function at each state for this domain? Is the optimal value function unique? Explain. What is the optimal policy at each state for this domain? Is the optimal policy unique? Explain. Suggest a change to the reward function that changes the value function but does not change the optimal policy
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts