Question: Overview This is a straight-forward assignment to read in a number of words from standard input in to a vector and output a subset of
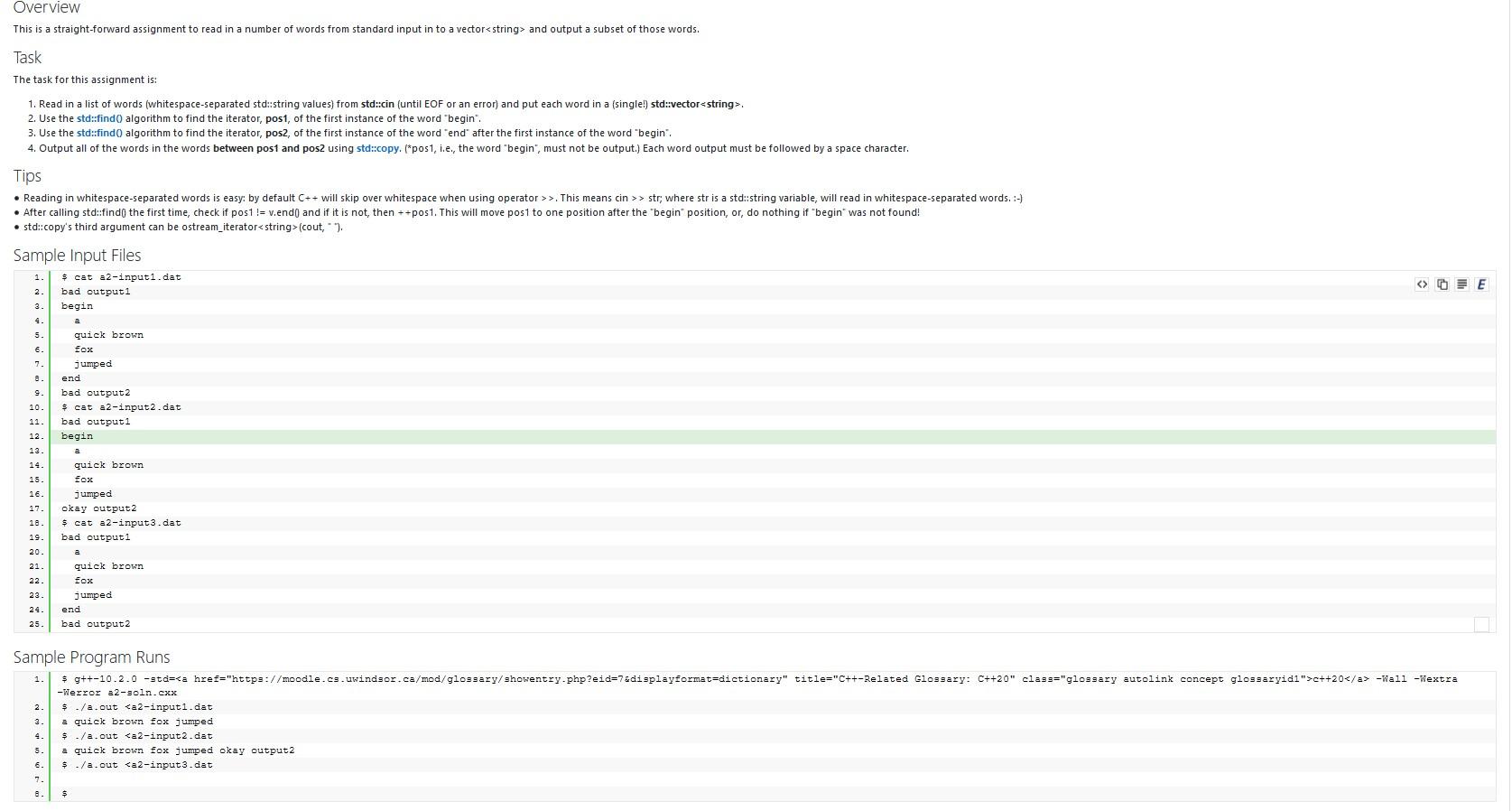
Overview This is a straight-forward assignment to read in a number of words from standard input in to a vector and output a subset of those words. Task The task for this assignment is: 1. Read in a list of words (whitespace-separated std::string values) from std::cin (until EOF or an error) and put each word in a single!) std::vector. 2. Use the std::find algorithm to find the iterator, post, of the first instance of the word begin". 3. Use the std::find algorithm to find the iterator, pos2, of the first instance of the word "end" after the first instance of the word "begin 4. Output all of the words in the words between post and pos2 using std::copy. (*post, i.e., the word "begin", must not be output.) Each word output must be followed by a space character. Tips Reading in whitespace-separated words is easy: by default C++ will skip over whitespace when using operator>>. This means cin >> str; where str is a std::string variable, will read in whitespace-separated words. :-) After calling std::find the first time, check if pos1 != v.endand if it is not, then +-pos1. This will move post to one position after the "begin position, or, do nothing if begin was not found! std::copy's third argument can be ostream_iterator(cout, Sample Input Files $ cat a2-input1.dat 2 bad outputi begin - quick brown FOX jumped end bad output2 $ cat a2-input2.dat bad outputi begin 10. quick brown fox jumped okay output2 $ cat a2-input3.dat bad output 1 19 20 22 quick brown fox jumped end 23 24 25 bad output2 1 Sample Program Runs $ g++-10.2.0 -std>c++20 -Wall -Wextra -Werror a 2-3oln. cxx $ ./a.out and output a subset of those words. Task The task for this assignment is: 1. Read in a list of words (whitespace-separated std::string values) from std::cin (until EOF or an error) and put each word in a single!) std::vector. 2. Use the std::find algorithm to find the iterator, post, of the first instance of the word begin". 3. Use the std::find algorithm to find the iterator, pos2, of the first instance of the word "end" after the first instance of the word "begin 4. Output all of the words in the words between post and pos2 using std::copy. (*post, i.e., the word "begin", must not be output.) Each word output must be followed by a space character. Tips Reading in whitespace-separated words is easy: by default C++ will skip over whitespace when using operator>>. This means cin >> str; where str is a std::string variable, will read in whitespace-separated words. :-) After calling std::find the first time, check if pos1 != v.endand if it is not, then +-pos1. This will move post to one position after the "begin position, or, do nothing if begin was not found! std::copy's third argument can be ostream_iterator(cout, Sample Input Files $ cat a2-input1.dat 2 bad outputi begin - quick brown FOX jumped end bad output2 $ cat a2-input2.dat bad outputi begin 10. quick brown fox jumped okay output2 $ cat a2-input3.dat bad output 1 19 20 22 quick brown fox jumped end 23 24 25 bad output2 1 Sample Program Runs $ g++-10.2.0 -std>c++20 -Wall -Wextra -Werror a 2-3oln. cxx $ ./a.out


