

Question: Problem 2. Relu activation with least squares loss Consider the network below for binary classification of labels +1 and -1. Let h=(hl=p+x.h2=g+x.h3=1+x) be the features
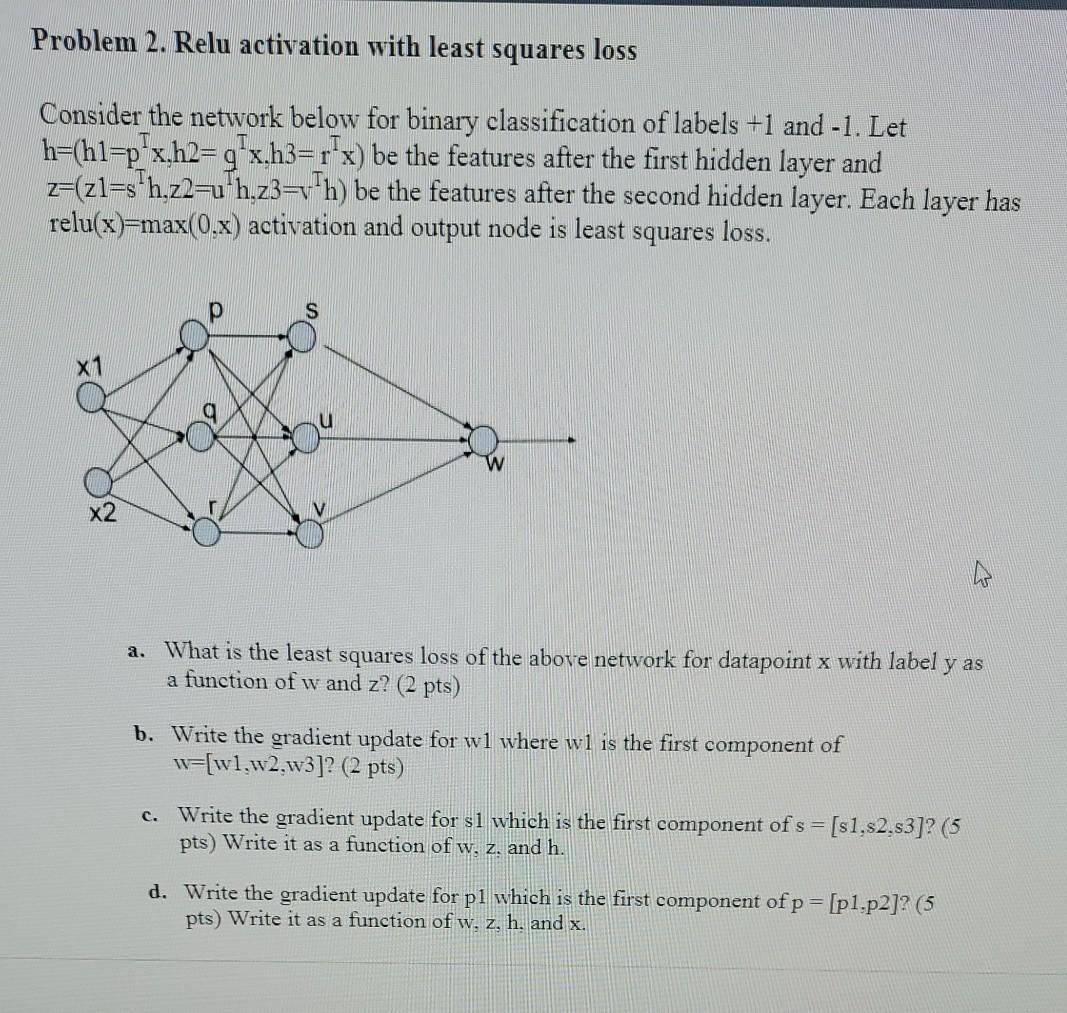
Problem 2. Relu activation with least squares loss Consider the network below for binary classification of labels +1 and -1. Let h=(hl=p+x.h2=g+x.h3=1+x) be the features after the first hidden layer and z=(zl=sh,z2= h.z3=vth) be the features after the second hidden layer. Each layer has relu(x)=max(0.x) activation and output node is least loss. squares X1 x2 a. What is the least squares loss of the above network for datapoint x with label y as a function of w and z? (2 pts) b. Write the gradient update for wl where wl is the first component of w=[wl.w2.w3]? (2 pts) c. Write the gradient update for sl which is the first component of s = [s1.s2.s3]? (5 pts) Write it as a function of w. z. and h. d. Write the gradient update for pl which is the first component of p = [p1.p2]? (5 pts) Write it as a function of w, z, h, and x. Problem 2. Relu activation with least squares loss Consider the network below for binary classification of labels +1 and -1. Let h=(hl=p+x.h2=g+x.h3=1+x) be the features after the first hidden layer and z=(zl=sh,z2= h.z3=vth) be the features after the second hidden layer. Each layer has relu(x)=max(0.x) activation and output node is least loss. squares X1 x2 a. What is the least squares loss of the above network for datapoint x with label y as a function of w and z? (2 pts) b. Write the gradient update for wl where wl is the first component of w=[wl.w2.w3]? (2 pts) c. Write the gradient update for sl which is the first component of s = [s1.s2.s3]? (5 pts) Write it as a function of w. z. and h. d. Write the gradient update for pl which is the first component of p = [p1.p2]? (5 pts) Write it as a function of w, z, h, and x
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts