

Question: Project Two: Hypothesis Testing and code in Python - Step 4 I am having trouble getting my code to work. It keeps coming up with
Project Two: Hypothesis Testing and code in Python - Step 4
I am having trouble getting my code to work. It keeps coming up with "dataframe" not specified. Is anyone able to provide some help with this?

This is the prompt for the assignment:
This was what I did for step 3:
And this is my code that I am trying to figure out in step 4:
import numpy as np from scipy.stats import ttest_1samp your_team_df = dataframe calc = np.random.normal(your_team_df) np.mean(calc)
team_mean = np.mean(your_team_df) print(team_mean) tset, pval = ttest_1samp(team_mean, 110) print("P Values") print(pval) if pval
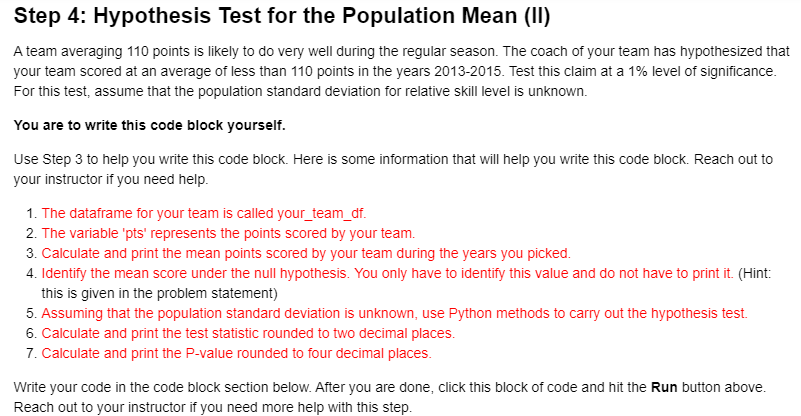
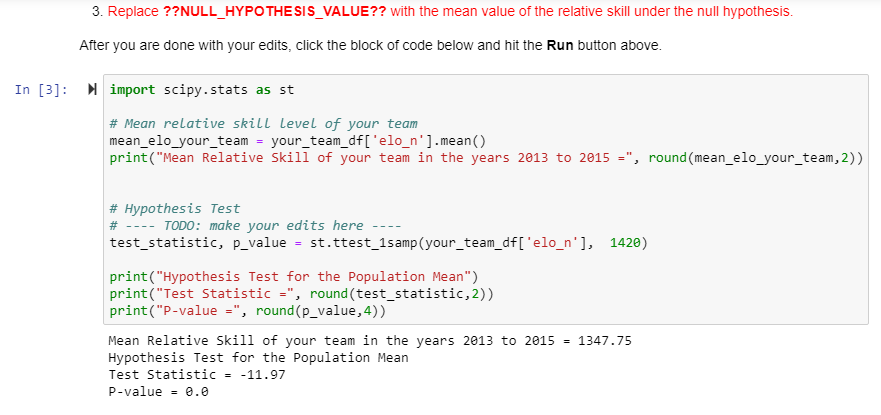
Traceback (most recent call last) NameError cell_name in async-def-wrapper() NameError: name 'dataframe' is not defined Step 4: Hypothesis Test for the population Mean (II) A team averaging 110 points is likely to do very well during the regular season. The coach of your team has hypothesized that your team scored at an average of less than 110 points in the years 2013-2015. Test this claim at a 1% level of significance. For this test, assume that the population standard deviation for relative skill level is unknown. You are to write this code block yourself. Use Step 3 to help you write this code block. Here is some information that will help you write this code block. Reach out to your instructor if you need help. 1. The dataframe for your team is called your_team_df. 2. The variable 'pts' represents the points scored by your team. 3. Calculate and print the mean points scored by your team during the years you picked. 4. Identify the mean score under the null hypothesis. You only have to identify this value and do not have to print it. (Hint: this is given in the problem statement) 5. Assuming that the population standard deviation is unknown, use Python methods to carry out the hypothesis test. 6. Calculate and print the test statistic rounded to two decimal places. 7. Calculate and print the P-value rounded to four decimal places. Write your code in the code block section below. After you are done, click this block of code and hit the Run button above. Reach out to your instructor if you need more help with this step. 3. Replace ??NULL_HYPOTHESIS_VALUE?? with the mean value of the relative skill under the null hypothesis. After you are done with your edits, click the block of code below and hit the Run button above. In [3]: import scipy.stats as st # Mean relative skill level of your team mean_elo_your_team = your_team_df['elo_n'].mean() print("Mean Relative Skill of your team in the years 2013 to 2015 =", round(mean_elo_your_team, 2)) # Hypothesis Test # ---- TODO: make your edits here ---- test_statistic, p_value = st.ttest_1samp(your_team_df['elo_n'], 1420) print("Hypothesis Test for the population Mean") print("Test Statistic =", round (test_statistic,2)) print("P-value =", round(p_value, 4)) Mean Relative Skill of your team in the years 2013 to 2015 = 1347.75 Hypothesis Test for the population Mean Test Statistic = -11.97 P-value = 0.0
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts