

Question: Python help, can only use import pickle and import nltk Create a class DocumentIndex to act as an abstract data type for the document index
Python help, can only use import pickle and import nltk
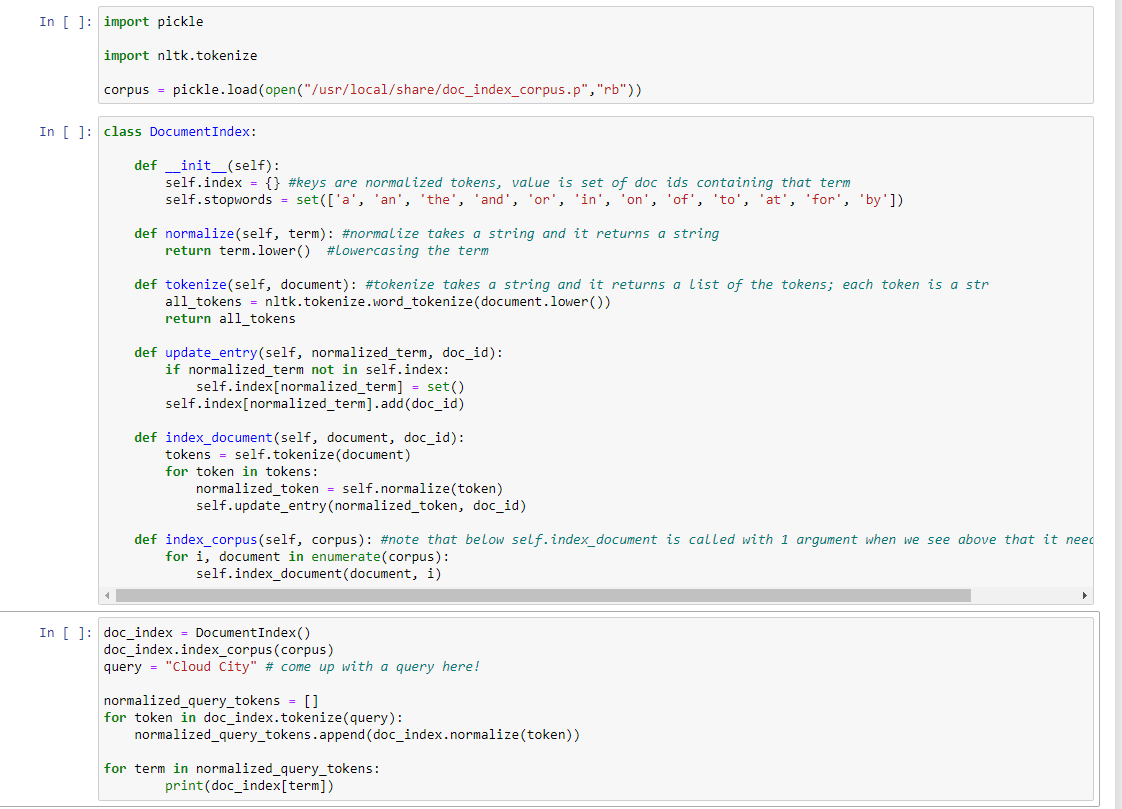
Create a class DocumentIndex to act as an abstract data type for the document index inverted index data structure. It should include the following member functions/support these operation on its data: A normalize(term) method that takes a str object term and returns a stemmed, lowercase version of that word suitable for a key in the inverted index. An update_entry(normalized_term, doc_id): method that adds the normalized str object normalized_term to the index if its not already in the index and records that the document with integral doc_id contains that term. A tokenize(document) method that takes a document as a str object and returns a list of unnormalized tokens contained in that document. Use a regex instead of split() for tokenization. An add_document(document, doc_id) method that takes a document as a str object with integral doc id and adds a tokenized, normalized version of the document to the inverted index. Stopwords in the document are not indexed. Note that when the spec says a tokenized, normalized version of the document gets indexed, that doesnt imply this method implements that. It implies this method causes that to happen. Note the other methods above implement this functionality, so they will be called by add_document(). A build_index(corpus) method that takes corpus as a list of str containing items that are the HTML of each document. Note that this corpus has no document ids, so use a documents index in the list as its ID here. An object of type Document_Index should support the operator [term] for term lookup. In other words, if object ii was constructed via ii = Document_Index() and a suitable index built with build_index(), then ii[Madison] would return the set of document IDs containing the search term Madison. Hint: magic methods By default, if a term is not in the index, it should return the empty set. There is a pickled list of documents you can use for testing. Its located in "/usr/local/share/doc index corpus.p" . You can access it via pickle.open() on ada. Below is a template:
import pickle class DocumentIndex: # you do this!
corpus = pickle.load(open("/usr/local/share/doc_index_corpus.p","rb")) doc_index = DocumentIndex() doc_index.build_index(corpus)
query = "" normalized_query_tokens = [doc_index.normalize(token) for token in doc_index.tokenize(query)]
for term in normalized_query_tokens: print(doc_index[term])
Heres the code I used to create the test corpus.
import pickle import urllib.request
import bs4
urls = ["https://starwars.fandom.com/wiki/Cloud_City", "https://screenrant.com/star-wars-bespin-facts/", "https://en.wikipedia.org/wiki/Cloud", "https://en.wikipedia.org/wiki/City" ]
corpus = [] for url in urls: with urllib.request.urlopen(url) as response: # request html_document = response.read() # read response from server soup = bs4.BeautifulSoup(html_document, "lxml") text_content = soup.get_text().replace(' ','').replace('\t','') corpus.append(text_content)
pickle.dump(corpus,open("doc_index_corpus.p","wb"))
----------------
Here is what I have so far:
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts