

Question: Q: In this query there was only 1 mapper and 1 reducer used for the entire counting process, which means that there was no parallelism
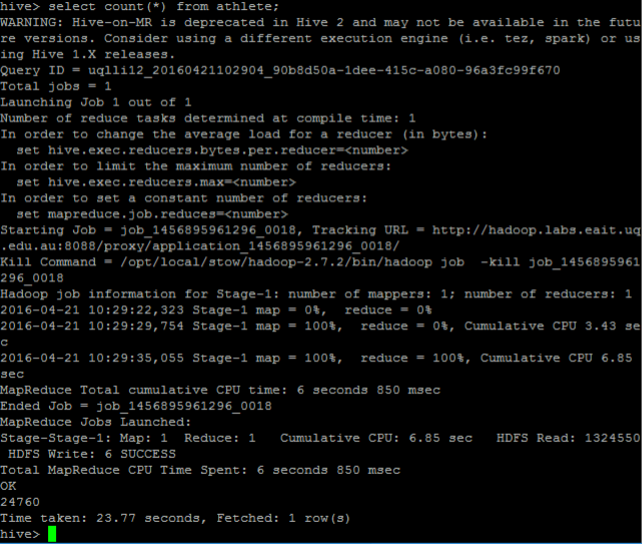
Q: In this query there was only 1 mapper and 1 reducer used for the entire counting process, which means that there was no parallelism used. Can a counting job like this be distributed across several nodes and in what scenario would this distribution occur?
hive> select count from athlete WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the futu re versions. Consider using a different execution engine (i.e tez, spark) or us ing Hive 1.X releases. Query ID ugl, li12 20160421102904 90b8d50a-1dee-415c-a080-96a3fc99 f670 Total jobs 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes) set hive .exec.reducers.bytes.per.reducer Knumber In order to limit the maximum number of reducers: set hive .exec. reducers .max Knumber In order to set a constant number of reducers: set mapreduce job. reduces
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts