

Question: Question 1 Consider the following feedforward neural network with one input layer, two hidden layers, and one output layer. The hidden neurons are ReLU units,
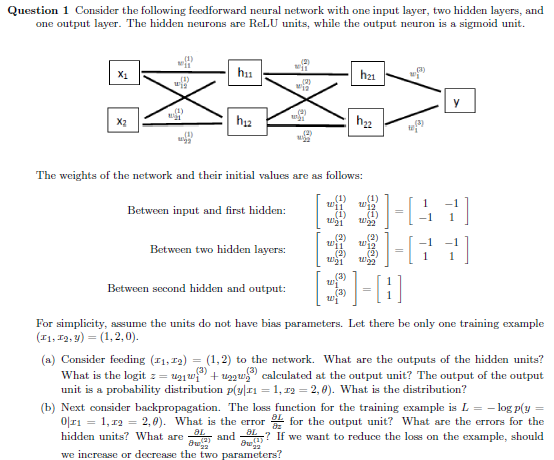
Question 1 Consider the following feedforward neural network with one input layer, two hidden layers, and one output layer. The hidden neurons are ReLU units, while the output neuron is a sigmoid unit. 2 (2 X2 i22 u The weights of the network and their initial values are as follows: 11 i2 21 Between input and first hidden: 11 i2 1 2 Between two hidden layers: Between second hidden and output: For simplicity, assume the units do not have bias parameters. Let there be only one training example (a) Consider feeding (ri, r2) (1,2) to the network. What are the outputs of the hidden units? What is the logit z = u21U13) + t 22w23) calculated at the output unit? The output of the output unit is a probability distribution pyi1,r 2,). What is the distribution? (b) Next consider backpropagation. The loss function for the training example is L =-log p(y = 0111 1,12 = 2,0). What is the error for the output unit? What are the errors for the hidden units? What are and ? If we want to reduce the loss on the example, should we increase or decrease the two parameters? Question 1 Consider the following feedforward neural network with one input layer, two hidden layers, and one output layer. The hidden neurons are ReLU units, while the output neuron is a sigmoid unit. 2 (2 X2 i22 u The weights of the network and their initial values are as follows: 11 i2 21 Between input and first hidden: 11 i2 1 2 Between two hidden layers: Between second hidden and output: For simplicity, assume the units do not have bias parameters. Let there be only one training example (a) Consider feeding (ri, r2) (1,2) to the network. What are the outputs of the hidden units? What is the logit z = u21U13) + t 22w23) calculated at the output unit? The output of the output unit is a probability distribution pyi1,r 2,). What is the distribution? (b) Next consider backpropagation. The loss function for the training example is L =-log p(y = 0111 1,12 = 2,0). What is the error for the output unit? What are the errors for the hidden units? What are and ? If we want to reduce the loss on the example, should we increase or decrease the two parameters
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts