

Question: solve this, Data Mining import pandas as pd import numpy as np data = { 'Student ID': [1, 2, 3, 4, 5], 'Name': ['Norah', 'Mohammed',
solve this, Data Mining
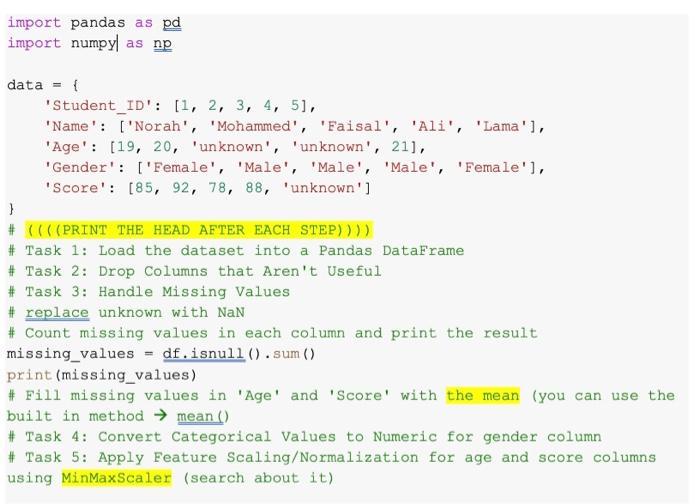
import pandas as pd import numpy as np data = { 'Student ID': [1, 2, 3, 4, 5], 'Name': ['Norah', 'Mohammed', 'Faisal', 'Ali', 'Lama'], 'Age' [19, 20, 'unknown', 'unknown', 21], 'Gender': ['Female', 'Male', 'Male', 'Male', 'Female'], 'Score': [85, 92, 78, 88, 'unknown'] } # ((((PRINT THE HEAD AFTER EACH STEP)))) #Task 1: Load the dataset into a Pandas DataFrame # Task 2: Drop Columns that Aren't Useful #Task 3: Handle Missing Values #replace unknown with NaN # Count missing values in each column and print the result missing_values = df.isnull().sum () print (missing_values) # Fill missing values in 'Age' and 'Score' with the mean (you can use the built in method mean () Task 4: Convert Categorical Values to Numeric for gender column #Task 5: Apply Feature Scaling/Normalization for age and score columns using MinMaxScaler (search about it)
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts