

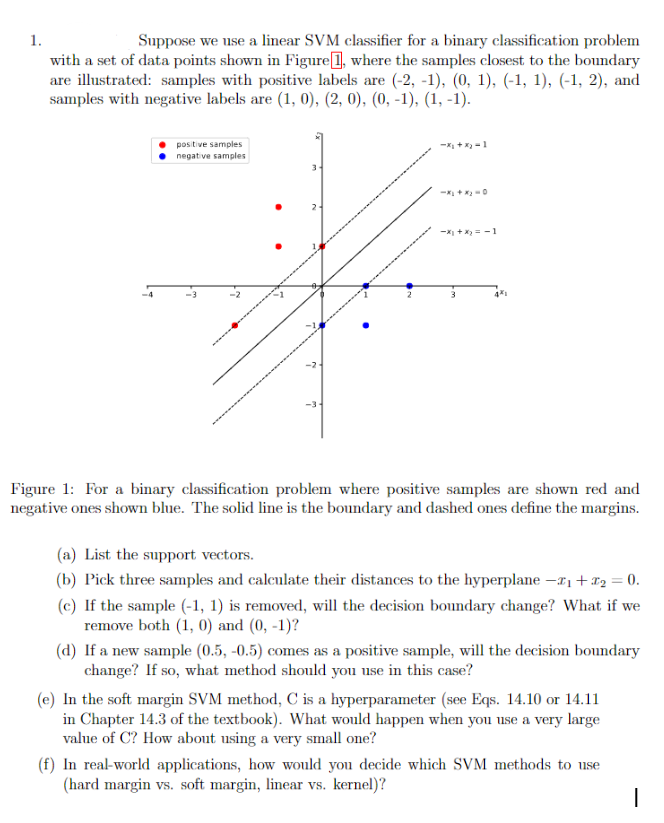
Question: Suppose we use a linear SVM classifier for a binary classification problem with a set of data points shown in Figure [ 1 , where
Suppose we use a linear SVM classifier for a binary classification problem
with a set of data points shown in Figure where the samples closest to the boundary
are illustrated: samples with positive labels are and
samples with negative labels are
Figure : For a binary classification problem where positive samples are shown red and
negative ones shown blue. The solid line is the boundary and dashed ones define the margins.
a List the support vectors.
b Pick three samples and calculate their distances to the hyperplane
c If the sample is removed, will the decision boundary change? What if we
remove both and
d If a new sample comes as a positive sample, will the decision boundary
change? If so what method should you use in this case?
e In the soft margin SVM method, C is a hyperparameter see Eqs. or
in Chapter of the textbook What would happen when you use a very large
value of How about using a very small one?
f In realworld applications, how would you decide which SVM methods to use
hard margin vs soft margin, linear vs kernel
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock