

Question: Using the information in the question and the code above, complete the table at the bottom. Superscalar: Consider a loop that is untilled 7 times
Using the information in the question and the code above, complete the table at the bottom.
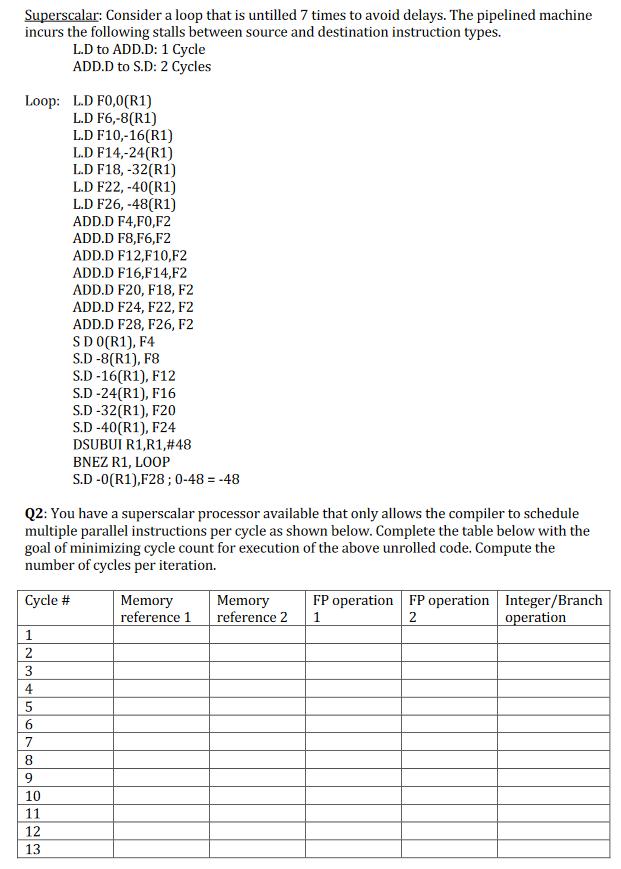
Superscalar: Consider a loop that is untilled 7 times to avoid delays. The pipelined machine incurs the following stalls between source and destination instruction types. L.D to ADD.D: 1 Cycle ADD.D to S.D: 2 Cycles Loop: L.D F0,0(R1) L.D F6,-8(R1) L.D F10,-16(R1) L.D F14,-24(R1) L.D F18, -32(R1) L.D F22, -40(R1) L.D F26, -48(R1) ADD.D F4,FO,F2 ADD.D F8,F6,F2 ADD.D F12, F10,F2 ADD.D F16,F14,F2 ADD.D F20, F18, F2 ADD.D F24, F22, F2 ADD.D F28, F26, F2 SD 0(R1), F4 S.D -8(R1), F8 S.D-16(R1), F12 S.D-24(R1), F16 S.D-32(R1), F20 S.D-40(R1), F24 DSUBUI R1,R1,#48 BNEZ R1, LOOP S.D-0(R1),F28; 0-48=-48 Q2: You have a superscalar processor available that only allows the compiler to schedule multiple parallel instructions per cycle as shown below. Complete the table below with the goal of minimizing cycle count for execution of the above unrolled code. Compute the number of cycles per iteration. Cycle # 1 2 FP operation FP operation Integer/Branch Memory Memory reference 1 reference 2 1 2 operation 3 4 5 6 7 8 9 10 11 12 13
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts