

Question: X _ train, X _ test, y _ train, y _ test = train _ test _ split , test _ size = 0 .
Xtrain, Xtest, ytrain, ytest traintestsplit testsize randomstate
# Define the column transformer for preprocessing
numericfeatures YrSold 'SaleType'
categoricalfeatures GarageCars PoolArea'
preprocessor ColumnTransformer
transformers
num MinMaxScaler numericfeatures
cat OneHotEncoder categoricalfeatures
# Create Random Forest pipeline
rfpipeline Pipelinestepspreprocessor preprocessor
regressor RandomForestRegressor
# Create KNearest Neighbors pipeline
knnpipeline Pipelinestepspreprocessor preprocessor
regressor KNeighborsRegressor
# Define hyperparameters grid for GridSearchcv
rfparamgrid
'regressornestimators :
'regressormaxdepth':
'regressorcriterion': mse 'mae'
knnparamgrid
'regressornneighbors':
'regressorweights': uniform 'distance'
# Perform GridSearchCV with fold cross validation for Random Forest
rfgridsearch GridSearchCVrfR
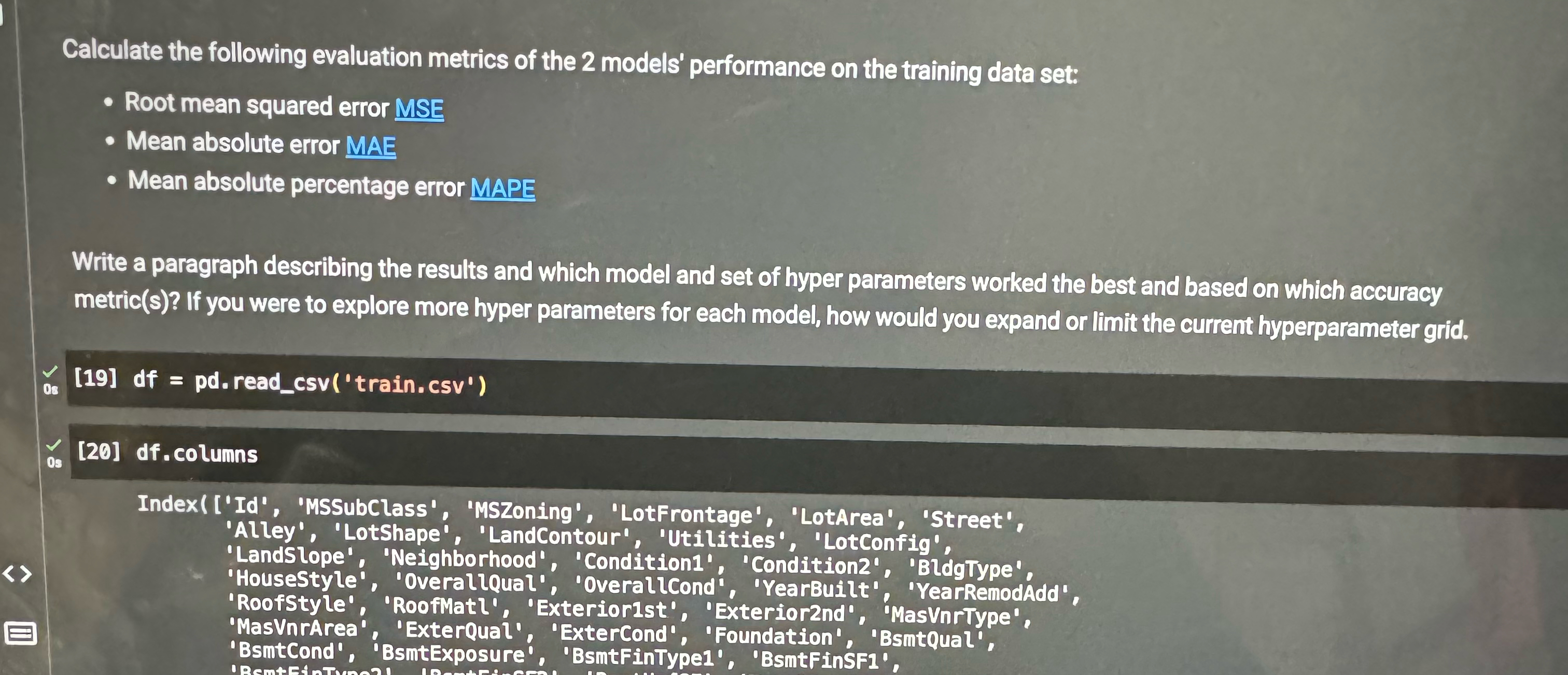
Calculate the following evaluation metrics of the models' performance on the training data set:
Root mean squared error MSE
Mean absolute error MAE
Mean absolute percentage error MAPE
Write a paragraph describing the results and which model and set of hyper parameters worked the best and based on which accuracy metrics If you were to explore more hyper parameters for each model, how would you expand or limit the current hyperparameter grid.
as
df pdreadcsvtraincsv
dfcolumns
Index Id 'MSSubClass', 'MSZoning', 'LotFrontage', 'LotArea', 'Street',
'Alley', 'LotShape', 'LandContour', 'Utilities', 'LotConfig',
'LandSlope', 'Neighborhood', 'Condition 'Condition 'BldgType',
'HouseStyle', 'Overallqual', 'Overalicond', 'YearBuilt', 'YearRemodAdd',
'RoofStyle', 'RoofMatl', 'Exteriorst 'Exteriornd 'MasVnrType',
'MasVnrArea', 'ExterQual': 'ExterCond', 'Foundation', 'BsmtQual',
'BsmtCond', 'BsmtExposure', 'BsmtFinType 'BsmtFinSFpipeline, rfparangrid, cv
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock