

Alice is an undergraduate student studying business at a UK university. Approaching final year, and her research
Question:
Alice is an undergraduate student studying business at a UK university. Approaching final year, and her research project, Alice was unsure as to which topic she would investigate. Deciding to play to her strengths, Alice noticed how much time she spent using social media, and in particular, the interaction she was having with her favourite brands via Twitter. She observed that brands were being promoted informally using such media, the interactions with consumers being wider than just responding to requests and complaints. Noting from her research methods class that she needed a robust justification for carrying out the research, Alice conducted a review of the marketing literature that examined Twitter data. Seeing the technique used in Business-to- Business research (e.g. Leek et al., 2016), and work on consumer complaint behaviour on Twitter and social media more generally (e.g. Ma et al. 2015; Istanbulluoglu 2017; Istanbulluoglu, Leek and Szmigin 2017), Alice decided to set her project somewhere within this broad research area. After a further examination of the existing literature, she ultimately chose to investigate the messages and sentiments that were being used to engage with consumers via Twitter.
Finding evidence of the validity of using Twitter data for monitoring brand perceptions (see Culotta & Cutler 2016), Alice decided to collect the tweets and retweets from three of her favourite brands, one in the fast-moving consumer goods category, a fitness brand and a telecoms service provider. Recognising that the tweets were accessible and in the public domain without needing a Twitter account, Alice felt the tweets were a viable, rich data source. Considering the tweets to be public, Alice did not discuss the ethical issues surrounding this decision with her supervisor, and started thinking about her data collection.
Alice spent some time looking for suitable, easy access software that she could use to collect the tweets, but did not find any free software that provided the data she wanted. However, Alice found Tweet Archivist Desktop, which allowed her to actively gather and store tweets from Twitter (a process known as ‘scraping’), but this required data to be collected in real time. This meant that if she wanted six months' worth of data, Alice would need to have the software running and collecting tweets for that period. Given the time limitations of her dissertation, she decided that a retrospective examination of tweets would be sufficient for her purpose. Alice went to the Twitter profile pages for the three brands and copied every tweet posted by the brand in the last six months. This approach allowed her to collect a sufficient sample of tweets in a matter of minutes, rather than months. She pasted the content into a word processor to save the data for later analysis.
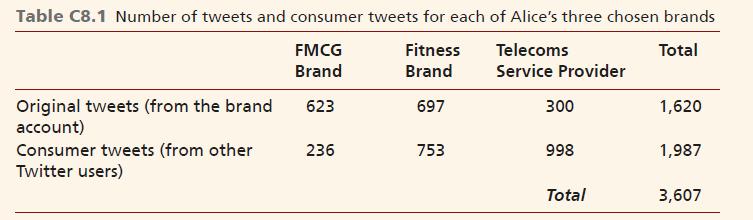
Alice counted all the tweets from the three brands for that period and realised that she had a large sample of 1,620 tweets. In addition, there were 1,987 tweets from other Twitter users interacting with the brand, making a total of 3,607 tweets in her sample. Alice tabulated these descriptive statistics (Table C8.1).
After discussing several options for data analysis with her project tutor, Alice decided to first identify tweets that were general, informal engagement with other users, and those that were complaints and responses, and thus of interest to her research objectives. Next, Alice decided to conduct content analysis on all the tweets to code them for the number of times a positive or negative interaction was mentioned, and the number of times this interaction then had a visible successful outcome for the consumer (for an example of similar research, see Einwiller & Steilen, 2015).
The analysis took Alice three months, as she needed to read each of the 3,607 tweets, make an interpretation as to its meaning and code it as either positive or negative, and whether there was a successful outcome. Alice wrote the following conclusion about her data analysis: Of the 3,607 tweets collected in this sample, 65.01% were positive interactions, of which 33.33% had a visible successful outcome for the consumer; and 34.99% were negative, of which 50.00% had a visible successful outcome for the consumer. Therefore, brands should use social media for engaging with consumers, as the majority of interactions are positive, and when brand-consumer interactions start off negatively, they often had a successful outcome for the consumer.
Questions
1 What issues can you see with Alice’s steps from idea generation to research design?
2 Consider the advantages and disadvantages of Alice’s sample selection technique.
3 When Alice’s research supervisor found that she had collected so many tweets in this way, she was concerned that Alice may have violated ethical procedures. Are Tweets (and similarly open social media data) really considered to be public, and does this mean it is acceptable to use these data for research?
4 By using tweets from Twitter, what legal concerns may exist over the ownership of the data?
5 Alice collected her data before considering or discussing her analysis techniques. What issues may arise here?
6 Given the richness of social media data, Alice’s project tutor felt the conclusions are somewhat basic, and perhaps not even suitable. What other techniques could Alice adopt to better utilise the source of data she has?
Step by Step Answer:



Research Methods For Business Students
ISBN: 9781292208787
8th Edition
Authors: Mark Saunders, Philip Lewis, Adrian Thornhill
