

Question: For data sets that contain many missing values, methods for estimating the missing values called imputation algorithms may be applied. In the journal,
For data sets that contain many missing values, methods for estimating the missing values — called imputation algorithms — may be applied. In the journal, Data & Knowledge Engineering (March 2013), researchers compared several imputation algorithms based on using nearest neighbors to estimate missing values. The five methods studied are named KMI, EACI, IKNNI, KNNI, and SKNN. Each of the methods was applied to each of four different data sets, one data set with 10% missing values, one with 30% missing, one with 50% missing, and one with 70% missing. After each imputation algorithm was applied, the normalized root mean square error (NRMSE) — a measure of the accuracy of the missing value predictions — was determined. These NRMSE values (based on information provided in the journal article) are given in the following table. Conduct a nonparametric analysis of the data. Is there evidence to indicate that the NRMSE distributions differ for the five imputation algorithms? Test using α = .01.
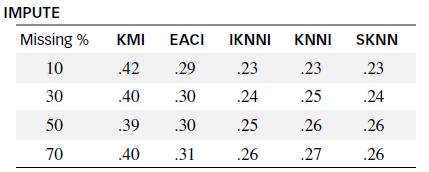
IMPUTE Missing % KMI EACI IKNNI KNNI SKNN 10 42 .29 .23 .23 .23 30 40 .30 24 .25 .24 50 .39 .30 .25 .26 26 70 .40 .31 .26 .27 .26
Step by Step Solution
3.48 Rating (155 Votes )
There are 3 Steps involved in it
To conduct a nonparametric analysis of the data and test whether the NRMSE distributions differ for the five imputation algorithms we can use a nonpar... View full answer

Get step-by-step solutions from verified subject matter experts