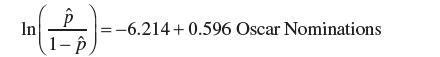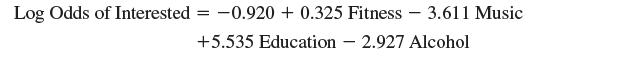New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
business
business analytics data
Business Analytics 5th Edition Jeffrey D. Camm, James J. Cochran, Michael J. Fry, Jeffrey W. Ohlmann - Solutions
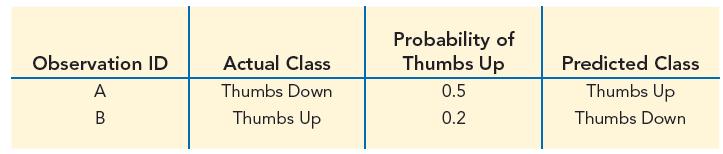
Which of the following statements about logistic regression is true?a. Logistic regression estimates the probability of an observation being in the “yes”class as a linear function of input variables.b. Logistic regression does not assume a functional relationship between a binary event and the
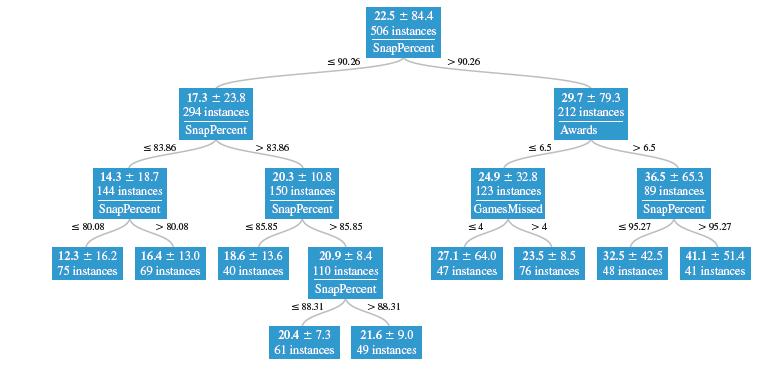
In Section 11.3, the logistic regression equation to predict whether a movie wins the Best Picture Academy Award based on the total number of Oscar nominations was:For a cutoff value of pˆ = 0.5, what is the decision boundary separating Class 1 from Class 0 observations for this model? Demonstrate
Which of the following statements about the k-nearest neighbors classifier is true?a. The decision boundary corresponding to a k-nearest neighbor classifier is a linear function of the input variables.b. The decision boundary corresponding to a k-nearest neighbor classifier can be a highly
For 10,000 observations, suppose a classifier generates 235 false positives, 138 false negatives, 9,432 true negatives, and 195 true positives. What is the classifier’s accuracy?
For 10,000 observations, suppose a classifier generates 235 false positives, 138 false negatives, 9,432 true negatives, and 195 true positives. What is the classifier’s sensitivity?
For 10,000 observations, suppose a classifier generates 235 false positives, 138 false negatives, 9,432 true negatives, and 195 true positives. What is the classifier’s specificity?
For 10,000 observations, suppose a classifier generates 235 false positives, 138 false negatives, 9,432 true negatives, and 195 true positives.What is the classifier’s precision?
An analyst for an insurance company’s data science team is developing a model to predict whether a submitted claim is fraudulent. Generally, less than 10% of claims are fraudulent. The threshold value for classifying an observation as fraudulent is not universally agreed upon. Which of the
When the threshold value for binary classification increases, what happens?a. Sensitivity decreases and specificity increases.b. F1 score increases.c. Precision increases.d. Accuracy decreases.
A sports betting company is testing the effectiveness of its online ads and has developed a classification model that predicts whether a potential customer will respond to its offer using information in the potential customer’s browser history (cookies, etc.). Out of a test dataset of 1,000
A sports betting company is testing the effectiveness of its online ads and has developed a classification model predicts whether a potential customer will respond to its offer using information in the potential customer’s browser history(cookies, etc.). For the top 10% of customers most likely
What happens if a classification tree is grown to its fullest extent?a. Each leaf node will be 100% pure (all Class 1 observations or all Class 0 observations)b. The best predictive performance on out-of-sample data will be achieved.c. Each leaf node will consist of a single observation.d. Training
It is known that tree-based learning is unstable.What does this mean?a. Trees are poor predictive models.b. The predictive performance of the tree varies dramatically based on the training data used.c. When the data used to train a tree is changed (even slightly), the variables (and their split
How are variables selected in tree-based learning?a. Variables are automatically selected by the tree logic as the best variable(and value to split it at) is identified at each step of the recursive partitioning.b. Variables must be selected in a preprocessing step using a filter method.c. A
Which of the following statements about bagging is false?a. Bagging generates a composite prediction by weighting the votes of the individual classifiers by their individual accuracies.b. Bagging generates a committee of different classifiers by constructing them from slightly different training
Which of the following statements about boosting is false?a. Boosting works best when using logistic regression models as the individual classifiers.b. Boosting constructs a sequence of classifiers for which the training set for classifier j + 1 depends on the prediction errors of classifiers j on
Suppose each individual classifier in an ensemble has a 70% chance of predicting an observation’s class correctly and that the individual classifiers are perfectly independent of each other. What is the probability that an ensemble of 11 such classifiers correctly predicts an observation’s
Why are trees often used as individual classifiers in an ensemble approach?a. Trees are computationally easy to construct.b. Trees are easy to interpret.c. Trees have embedded feature selection.d. Trees are unstable predictors.
Which of the following statements about random forests is false?a. The predictive performance of a random forest is often competitive with a boosting ensemble, and it is computationally much simpler.b. A random forest is an ensemble consisting of a combination of different types of classifiers
Which of the following statements about the architecture of a neural network is false?a. The output layer of a neural network for a binary classification task produces an observation’s probability of a Class 1 outcome.b. The activation function in the output layer of a neural network for a
Which function is a common choice for the output layer in a neural network for a classification task?a. Logistic functionb. Identity functionc. ReLu functiond. Quadratic function
In a filter method, which of the following is helpful to assess the relationship between a quantitative input variable and a categorical outcome variable?a. Test of independenceb. ROC curvec. Scatter chartd. Boxplots
For which classification method is a lasso regularization commonly used to select features?a. k-nearest neighborsb. Classification treesc. Logistic regressiond. Random forest
The dating web site Oollama.com requires its users to create profiles based on a survey in which they rate their interest (on a scale from 0 to 3) in five categories: physical fitness, music, spirituality, education, and alcohol consumption. A new Oollama customer, Erin O’Shaughnessy, has
Fleur-de-Lis is a boutique bakery specializing in cupcakes. The bakers at Fleur-de-Lis like to experiment with different combinations of four major ingredients in its cupcakes and collect customer feedback; it has data on 150 combinations of ingredients with the corresponding customer reception for
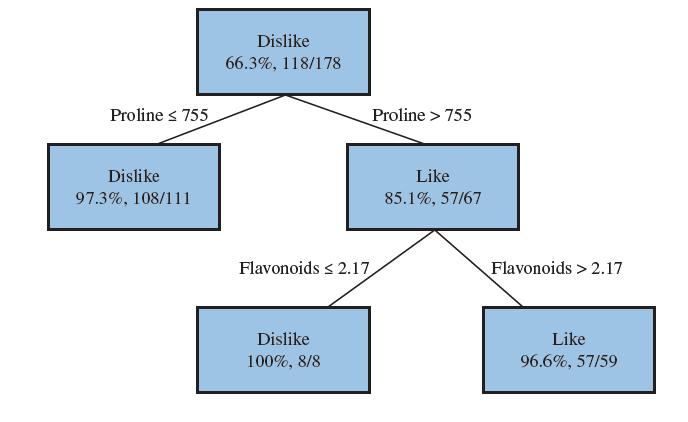
Sommelier4U is a company that ships its customers bottles of different types of wine and then has the customers rate the wines as “Like” or“Dislike.” For each customer, Sommelier4U trains a classification tree based on the characteristics of the wine such as amount of proline and flavonoids
A university is applying classification methods in order to identify alumni who may be interested in donating money. The university has a database of 58,205 alumni profiles containing numerous variables. Of these 58,205 alumni, only 576 have donated in the past. The university has oversampled the
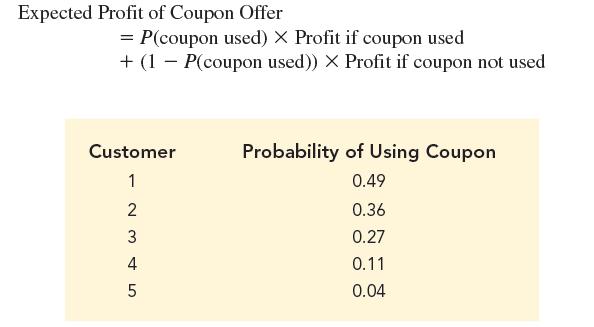
Honey is a technology company that provides online coupons to its subscribers. Honey’s analytics staff has developed a classification method to predict whether a customer who has been sent a coupon will apply the coupon toward a purchase. For a sample of customers, the following table lists the
Watershed is a media services company that provides online streaming movie and television content. As a result of the competitive market of streaming service providers, Watershed is interested in proactively identifying who will unsubscribe in the next three months based on the customer’s
Salmons Stores operates a national chain of women’s apparel stores. Five thousand copies of an expensive four-color sales catalog have been printed, and each catalog includes a coupon that provides a $50 discount on purchases of $200 or more. Salmons would like to send the catalogs only to
Refer to the scenario in Problem 30 regarding the identification of coupon promotion responders. Apply k-nearest neighbors to classify observations as a promotion-responder or not by using Coupon as the target (or response) variable. Set aside 20% of the data as a test set and use 80% of the data
Refer to the scenario in Problem 30 regarding the identification of coupon promotion responders. Apply a classification tree to classify observations as a promotion-responder or not by using Coupon as the target (or response) variable. Set aside 20% of the data as a test set and use 80% of the data
Refer to the scenario in Problem 30 regarding the identification of coupon promotion responders. Apply a neural network to classify observations as a promotion-responder or not by using Coupon as the target (or response)variable. Set aside 20% of the data as a test set and use 80% of the data for
Over the past few years the percentage of students who leave Dana College at the end of their first year has increased. Last year, Dana started voluntary one-credit hour-long seminars with faculty to help first-year students establish an on-campus connection. If Dana is able to show that the
Refer to the scenario in Problem 34 regarding the identification of students who drop out of school. Apply k-nearest neighbors to classify observations as a drop-out or not by using Dropped as the target (or response) variable. Use 100% of the data for training and validation (do not use any data
Refer to the scenario in Problem 34 regarding the identification of students who drop out of school. Apply a classification tree to classify observations as a drop-out or not by using Dropped as the target (or response)variable. Use 100% of the data for training and validation (do not use any data
Refer to the scenario in Problem 34 regarding the identification of students who drop out of school. Apply a neural network to classify observations as a drop-out or not by using Dropped as the target (or response)variable. Use 100% of the data for training and validation (do not use any data as a
Sandhills Bank would like to increase the number of customers who use paperless banking as part of the rollout of its e-banking platform. Management has proposed offering an increased interest rate on a savings account if customers enroll for comprehensive paperless banking. To forecast the success
Refer to the scenario in Problem 38 regarding the identification of bank customers who enroll in paperless banking.Apply k-nearest neighbors to classify observations as enrolling or not by using Enroll as the target (or response) variable. Use 100% of the data in the file plains for training and
Refer to the scenario in Problem 38 regarding the identification of bank customers who enroll in paperless banking.Apply a classification tree to classify observations as enroll or not by using Enroll as the target (or response) variable. Use 100% of the data for training and validation (do not use
Refer to the scenario in Problem 38 regarding the identification of bank customers who enroll in paperless banking. Apply a neural network to classify observations as a enroll or not by using Enroll as the target(or response) variable. Use 100% of the data for training and validation (do not use
Campaign organizers for both the Republican and Democratic parties are interested in identifying individual undecided voters who would consider voting for their party in an upcoming election. A non-partisan group has collected data on a sample of voters with tracked variables. The variables in this
Refer to the scenario in Problem 42 regarding the identification of undecided voters. Apply k-nearest neighbors to classify observations as undecided or not by using Vote as the target (or response) variable. Set aside 20% of the data as a test set and use 80% of the data for training and
Refer to the scenario in Problem 42 regarding the identification of undecided voters. Apply a classification tree to classify observations as undecided or not by using Vote as the target (or response) variable. Set aside 20% of the data as a test set and use 80% of the data for training and
Refer to the scenario in Problem 42 regarding the identification of undecided voters. Apply a random forest to classify observations as undecided or not by using Vote as the target (or response) variable. Set aside 20% of the data as a test set and use 80% of the data for training and validation.a.
Refer to the scenario in Problem 42 regarding the identification of undecided voters. Apply a neural network to classify observations as undecided or not by using Vote as the target (or response) variable.Set aside 20% of the data as a test set and use 80% of the data for training and validation.a.
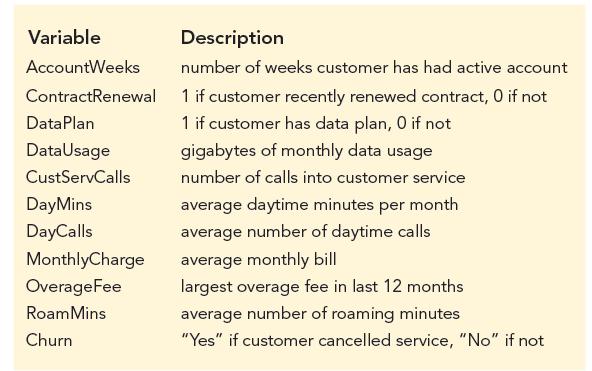
Telecommunications companies providing cell-phone service are interested in customer retention. In particular, identifying customers who are about to churn (cancel their service) is potentially worth millions of dollars if the company can proactively address the reason that customer is considering
Refer to the scenario in Problem 47 regarding the identification of churning cellphone customers. Apply k-nearest neighbors to classify observations as churning or not by using Churn as the target (or response) variable. Set aside 20% of the data as a test set and use 80% of the data for training
Refer to the scenario in Problem 47 regarding the identification of churning cellphone customers. Apply a classification tree to classify observations as churning or not by using Churn as the target (or response) variable. Set aside 20% of the data as a test set and use 80% of the data for training
Refer to the scenario in Problem 47 regarding the identification of churning cellphone customers. Apply a random forest to classify observations as churning or not by using Churn as the target (or response) variable. Set aside 20% of the data as a test set and use 80% of the data for training and
Refer to the scenario in Problem 47 regarding the identification of churning cellphone customers. Apply a neural network to classify observations as churning or not by using Churn as the target (or response) variable. Set aside 20% of the data as a test set and use 80% of the data for training and
Each year, the American Academy of Motion Picture Arts and Sciences recognizes excellence in the film industry by honoring directors, actors, and writers with awards (called “Oscars”) in different categories. The most notable of these awards is the Oscar for Best Picture. Data has been
Refer to the scenario in Problem 52 regarding the identification of movies that win the Best Picture Oscar. Apply k-nearest neighbors to classify observations as winning best picture or not by using Winner as the target (or response) variable. Use 100% of the data for training and validation (do
Refer to the scenario in Problem 52 regarding the identification of movies that win the Best Picture Oscar. Apply a classification tree to classify observations as winning best picture or not by using Winner as the target (or response) variable. Use 100% of the data for training and validation(do
Refer to the scenario in Problem 52 regarding the identification of movies that win the Best Picture Oscar. Apply a random forest to classify observations as winning best picture or not by using Winner as the target (or response) variable. Use 100% of the data for training and validation (do not
Refer to the scenario in Problem 52 regarding the identification of movies that win the Best Picture Oscar. Apply a neural network to classify observations as winning best picture or not by using Winner as the target (or response) variable. Use 100% of the data for training and validation (do not
Consider the following time series data. Quarter Year 1 Year 2 Year 3 1 4 6 7 2 2 3 3 3 5 4 5 7 868 6
Which of the following statements is false?a. RMSE and MAE often agree on which regression model is the most accurate.b. RMSE and MAE both indicate when the predicted values are consistently larger than the actual values.c. RMSE will penalize a prediction method for a large prediction error more
What is a benefit of k-fold cross-validation over the static holdout method?a. The k-fold cross-validation method is computationally faster.b. The k-fold cross-validation method is easier to implement when the standardization or normalization of variables is required.c. For k = 1, the k-fold
Why is the k-nearest neighbors regression called a lazy learner?a. Because k-nearest neighbors does not have embedded feature selection.b. Because the k-nearest neighbors regression requires the standardization or normalization of the variables.c. Because the k-nearest neighbors regression does not
Which of the following statements about k-nearest neighbors regression is false?a. The choice of input features may have an impact on predictive performance.b. Variables do not need to be standardized.c. If too large of a value of k is selected, prediction error will be large due to underfitting.d.
When splitting a node of a regression tree into two subsets, how are the variable and its split value determined?a. At each step, the variable and its split value that are selected result in the largest decrease in the variance of the outcome variable.b. The variable that has a split value with the
Why is it generally a good idea to prune a full regression tree?a. A full regression tree is too large to visualize.b. A full regression tree typically overfits the training data and pruning the tree improves the predictive performance on validation data.c. Pruning a tree by applying restrictions
Which of the following statements is true?a. A bagging ensemble is more computationally expensive than a boosting ensemble.b. An ensemble method requires a collection of strong, stable individual learners to be effective.c. Random forests try to decorrelate their constituent regression trees by
Which of the following statements about ensemble methods is false?a. In a boosting ensemble, the training data for an individual model depends on the predictions of the previously constructed individual models.b. A bagging ensemble generates a composite prediction by averaging individual
Which of the following statements about the architecture of a neural network is false?a. The output layer of a neural network for a regression task commonly consists of only one neuron.b. The number of neurons in the input layer typically corresponds to the number of variables under
Which of the following statements about neural networks is false?a. It can be very easy to overfit a neural network due to number of weights to be estimated and the number of ways these weights are combined.b. A neuron’s output in a neural network is generated by applying an activation function
Which of the following statements about the training of a neural network is false?a. The training of a neural network is an iterative process of predicting an observation or batch of observations and then updating neuron weights based on a function of the prediction error.b. The performance of a
Which of the following statements is true?a. Filter methods are guaranteed to determine the best set of variables to include in a model.b. The best subsets method is an example of a wrapper method.c. Regularization is used with k-nearest neighbors regression to prevent too large of a value of k
Which of the following statements is true?a. Lasso regularization and ridge regularization are different methods for standardizing variables.b. Lasso regularization may prevent overfitting of a linear regression model by driving the coefficients of some variables to zero.c. Regularization is not
Casey Deesel is a sports agent negotiating a contract for Titus Johnston, an athlete in the National Football League (NFL). An important aspect of any NFL contract is the amount of guaranteed money over the life of the contract. Casey has gathered data on NFL athletes who have recently signed new
A consumer advocacy agency, Equitable Ernest, is interested in providing a service that allows an individual to estimate their own credit score (a continuous measure used by banks, insurance companies, and other businesses when granting loans, quoting premiums, and issuing credit). The file
A consumer advocacy agency, Equitable Ernest, is interested in providing a service that allows an individual to estimate their own credit score (a continuous measure used by banks, insurance companies, and other businesses when granting loans, quoting premiums, and issuing credit). The file
A consumer advocacy agency, Equitable Ernest, is interested in providing a service that allows an individual to estimate their own credit score (a continuous measure used by banks, insurance companies, and other businesses when granting loans, quoting premiums, and issuing credit). The file
A consumer advocacy agency, Equitable Ernest, is interested in providing a service that allows an individual to estimate their own credit score (a continuous measure used by banks, insurance companies, and other businesses when granting loans, quoting premiums, and issuing credit). The file
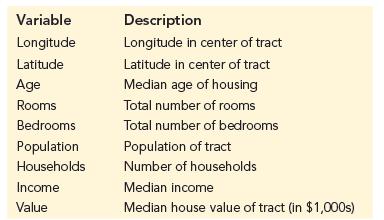
CD Real Estate specializes in residential real estate services in the state of California. To complement the experience and local market knowledge of its licensed realtors, CD Real Estate wants to develop an analytical tool to predict the value of real estate. The file calireal contains data on
CD Real Estate specializes in residential real estate services in the state of California. To complement the experience and local market knowledge of its licensed realtors, CD Real Estate wants to develop an analytical tool to predict the value of real estate. The file calireal contains data on
CD Real Estate specializes in residential real estate services in the state of California. To complement the experience and local market knowledge of its licensed realtors, CD Real Estate wants to develop an analytical tool to predict the value of real estate. The file calireal contains data on
CD Real Estate specializes in residential real estate services in the state of California. To complement the experience and local market knowledge of its licensed realtors, CD Real Estate wants to develop an analytical tool to predict the value of real estate. The file calireal contains data on
CD Real Estate specializes in residential real estate services in the state of California. To complement the experience and local market knowledge of its licensed realtors, CD Real Estate wants to develop an analytical tool to predict the value of real estate. The file calireal contains data on
Palanquin Auto is a national pre-owned car retailer that offers an online marketplace for customers interested in purchasing a preowned automobile. In an effort to reduce price negotiation, Palanquin collects data on automobile sales in an effort to set fair, competitive prices. The file palanquin
Palanquin Auto is a national pre-owned car retailer that offers an online marketplace for customers interested in purchasing a preowned automobile. In an effort to reduce price negotiation, Palanquin collects data on automobile sales in an effort to set fair, competitive prices. The file palanquin
Palanquin Auto is a national used car retailer that offers an online marketplace for customers interested in purchasing a preowned automobile. In an effort to reduce price negotiation, Palanquin collects data on automobile sales in an effort to set fair, competitive prices. The file palanquin
Palanquin Auto is a national pre-owned car retailer that offers an online marketplace for customers interested in purchasing a pre-owned automobile. In an effort to reduce price negotiation, Palanquin collects data on automobile sales in an effort to set fair, competitive prices. The file palanquin
Palanquin Auto is a national pre-owned car retailer that offers an online marketplace for customers interested in purchasing a pre-owned automobile. In an effort to reduce price negotiation, Palanquin collects data on automobile sales in an effort to set fair, competitive prices.The file palanquin
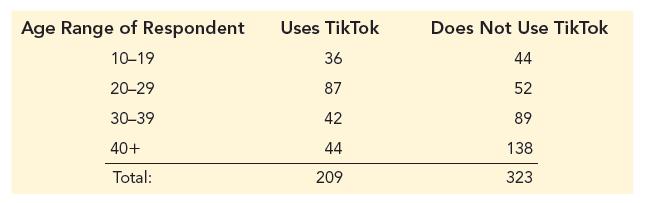
It is estimated that nearly half of all users of the social networking platform TikTok in the United States were between the ages of 10 and 29 in 2020 (Statista.com website). Suppose that the results below were received from a survey sent to a random sample of people in the United States regarding
Consider the random experiment of rolling a pair of six-sided dice. Suppose that we are interested in the sum of the face values showing on the dice.a. How many outcomes are possible?b. List the outcomes.c. What is the probability of obtaining a value of 7?d. What is the probability of obtaining a
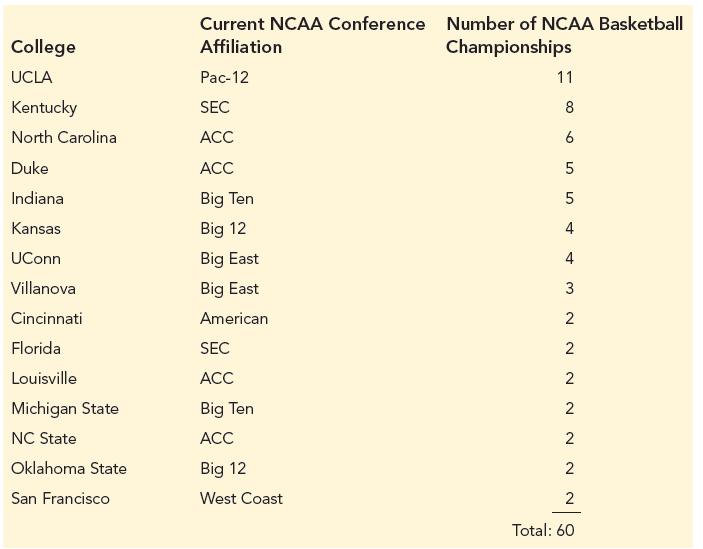
Only 15 college basketball programs have won more than a single NCAA Basketball Championship. Those 15 colleges are shown below along with their current NCAA Conference Affiliation and the number of NCAA Basketball Championships they have won. Suppose that the winner of one of these 60 NCAA
More than 1.5 million tests for the COVID virus were performed each day in the United States during the COVID-19 pandemic in 2021. Many employers, schools, and government agencies required negative COVID-19 tests before allowing people on their premises. Suppose that for a particular COVID-19 test,
Internal auditors are often used to review an organization’s financial statements such as balance sheets, income statements, and cash flow statements prior to public filings. Auditors seek to verify that the financial statements accurately represent the financial position of the organization and
According to the American Veterinary Medical Association (AVMA), 38.4% of households in the United States own a dog as a pet (AVMA website). Suppose that a company that sells dog food would like to establish a focus group to gather input on a new dog food marketing campaign. The company plans to
The book Code Complete by Steve McDonnell estimates that there are 15 to 50 errors per 1,000 lines of delivered code for computer programs.Assume that for a particular software package, the error rate is 25 per 1,000 lines of code and that the number of errors per 1,000 lines of code follows a
The United States Centers for Disease Control and Prevention (CDC) recommends that adults sleep seven to nine hours per night (CDC.gov website).However, many adults in the United States sleep less than seven hours per night. Suppose that the amount of sleep per night for an adult in the United
Laffy Taffy is a type of taffy candy made from corn syrup, sugar, palm oil, and other ingredients. Laffy Taffy comes in a variety of flavors including strawberry, banana, and cherry. Suppose that Laffy Taffy is produced as a continuous length of taffy on an extrusion machine. Defects can occur in
Which of the following statements about principal component analysis is true?a. A strength of PCA is the interpretability of its output.b. At least four components are necessary to satisfactorily explain the variance in a data set.c. PCA is a predictive method.d. Each additional principal component
What is an appropriate choice of distance metric for observations consisting of binary variables for which matching zeroes do not correspond to similarity?a. Matching distanceb. Jaccard distancec. Euclidean distanced. Cosine distance
When may cosine distance be a good choice to measure differences between observations?a. When dealing with observations with variables with both quantitative and categorical variables.b. When dealing with observations consisting of binary variables.c. When similarity in the pattern of variable
Which of the following is a true statement about the comparison of Euclidean distance versus Manhattan distance?a. Manhattan distance is distorted less by outlier observations.b. Euclidean distance is more applicable to binary variables.c. Manhattan distance scales better to higher dimensions.d.
Which of the following statements about hierarchical clustering is true?a. Because of its nested design, hierarchical clustering will find the set of k clusters that maximizes the average silhouette meaure for all possible values of k.b. For the same number of clusters and same distance measure,
What is a recommended criterion to determine the number of clusters in a k-means approach?a. Silhouette score.b. Elbow method.c. Corresponding set of k clusters has an intuitive interpretation and does not change when input data is slightly changed.d. All of these.
Showing 3200 - 3300
of 4107
First
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
Last
Step by Step Answers