

Question: This exercise is intended to help you understand the cost/complexity/ performance trade-off s of forwarding in a pipelined processor. Problems in this exercise refer to
Figure 4.45

1. If we use no forwarding, what fraction of cycles are we stalling due to data hazards?
2. If we use full forwarding (forward all results that can be forwarded), what fraction of cycles are we staling due to data hazards?
3. Let us assume that we cannot afford to have three input Muxes that are needed for full forwarding. We have to decide if it is better to forward only from the EX/MEM pipeline register (next-cycle forwarding) or only from the MEM/WB pipeline register (two-cycle forwarding). Which of the two options results in fewer data stall cycles?
4. For the given hazard probabilities and pipeline stage latencies, what is the speedup achieved by adding full forwarding to a pipeline that had no forwarding?
5. What would be the additional speedup (relative to a processor with forwarding) if we added time-travel forwarding that eliminates all data hazards? Assume that the yet-to-be-invented time-travel circuitry adds 100 ps to the latency of the full-forwarding EX stage.
6. Repeat 4.12.3 but this time determine which of the two options results in shorter time per instruction.
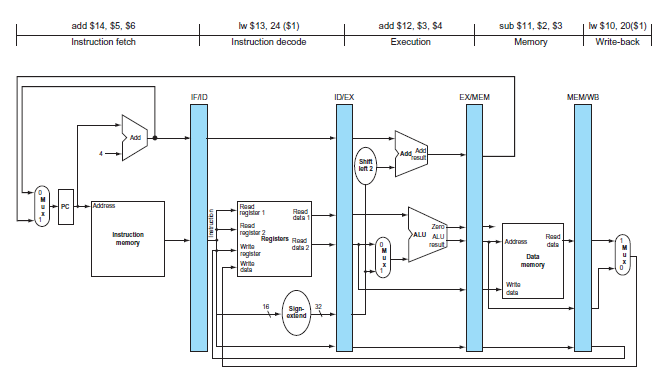
sub $11, $2, $3 Iw $13, 24 ($1) Iw $10, 20(S1) add $14, $5, $6 add $12, $3, $4 Instruction fetch Instruction decode Execution Memory Write-back MEMWB IFAD IDVEX EXMEM Add Ags A Trosuth Shift let 2 Addrass Read Taghlar Read data Read Zero ALU ALU ragistar 2 Registors Ruad Write agistar Instruction Read Addross momory resut data data 2 Data Write data memory Write data 16 Sign- axtand EX (FW from MEM/ WB only) EX EX EX (FW from (no FW) (full FW) EX/MEM only) MEM WB IF ID 150 ps 130 ps 120 ps 100 ps 100 ps 120 ps 150 ps 140 ps
Step by Step Solution
3.44 Rating (163 Votes )
There are 3 Steps involved in it
1 Dependences to the 1 st next instruction result in 2 stall cycles and the stall is also 2 cycles i... View full answer

Get step-by-step solutions from verified subject matter experts